
The SAP HANA database is full of power and is very stable, but anyone that works with software knows that sometimes the worst-case scenario happens and things get lost.
Recoverability of a database means that in the event of a database failure, the deployment is restored to the point at which the failure occurred. This is one of the most important considerations for a transactional system such as SAP S/4HANA and must be planned for properly.
Because the SAP HANA platform uses most data in-memory for best performance, in the case of a power failure, this data may be lost. However, there is persistent storage as well to protect against such failures. During normal operations, data is stored from the memory to the disk at regular intervals. This creates a savepoint.
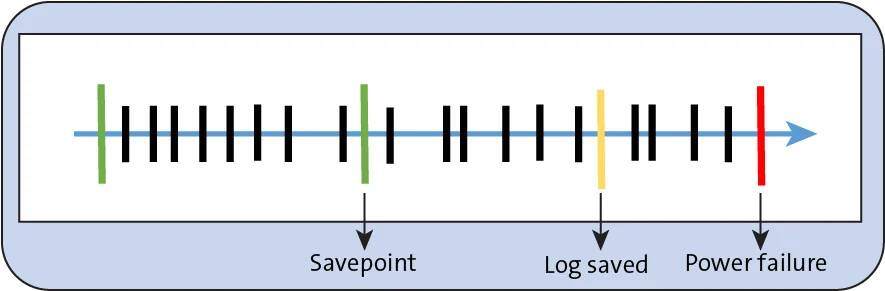
In addition, logs are written for any change in data after each operation. The log data is also saved to the disk after each transaction commit. Therefore, in the case of a power failure, the database can be restarted like any other database and takes into account this log data after the last savepoint. This helps to maintain the database consistency.
Recoverability, in turn, is closely linked to the term availability. Availability indicates the operational continuity of the system and is measured as a reverse function of system downtime, expressed as a percentage. There are two other aspects that may be needed for the SAP HANA database in the case of a disk or data center failure: high availability (HA) and disaster recovery (DR).
SAP states that HA “increases the failure tolerance within one data center by providing a fast switch over to an operational state of the SAP HANA database.” HA indicates a set of techniques and plans for business continuity in case of server failure. DR is the process of recovering operations at a different data center after a server failure that is due to a site or data center failure.
There are two key performance indicators (KPIs) associated with recovery:
- Recovery point objective (RPO): RPO refers to the maximum permissible period during which data may be lost between the last backup and the system crash.
- Recovery time objective (RTO): RTO refers to the maximum possible time elapsed between the system unavailability and the system being operative again.
The following information describe the various options for making a system HA and/ or DR. These options have different RPOs, RTOs, and costs.
Backup and Recovery (High Availability/Disaster Recovery)
Backups are necessary for database restoration in case of disk failures, to restore the database to an earlier point in time, or for database copy. Backups need to be made for data and log volumes and can be manual or automated. SAP HANA also synchronizes the data backup across multiple nodes and services without manual intervention.
All services that require data to be persisted are backed up. Data backup happens when the database is running, and transactions are stopped only for a very short time when the backup is initiated. There are various options to perform a data and log backup, which can be configured through SAP HANA cockpit:
- Backing up to file systems—for example, to a Network File System (NFS) share (SAP Note 1820529).
- Backing up to a third-party backup server through implementation of the Backint for SAP HANA application programming interface (API) by an SAP-certified third-party agent. Refer to SAP Note 2031547 for an overview of SAP-certified third-party backup tools and the associated support process.
- Backing up as a storage snapshot to external storage.
- Recovery to the most recent state using data backup or storage snapshot and using the log backups post for that backup point and entries if still available in the log area.
- Recovery to a specific point in time by using the data backup or storage snapshot from that point in time and the log backups post for that backup point and entries if still available in the log area.
- Recovery using data backup or a storage snapshot at a specific time but without log backups for the time thereafter and without any log entries beyond that point.
During recovery, the SAP HANA database is shut down. The progress and the actions can be initiated and checked using SAP HANA cockpit. For this option, the costs are comparatively lower, but it has an RPO greater than zero and a high RTO.
SAP HANA Storage Replication (Disaster Recovery)
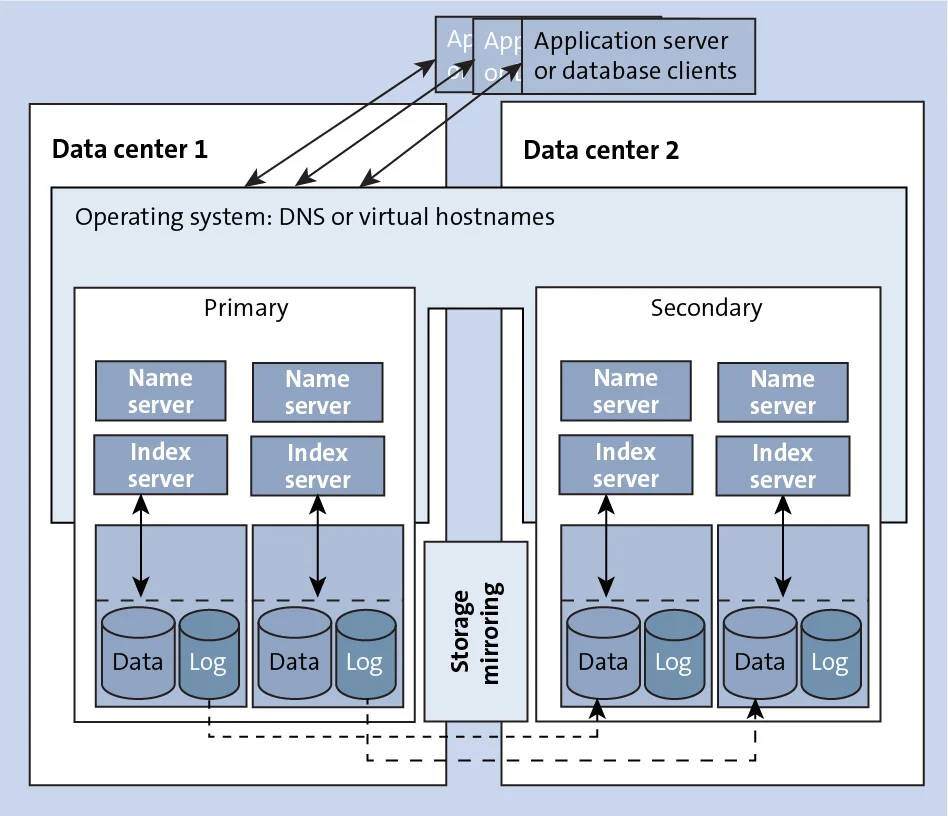
This option enables continuous replication of all persisted data, including the data and the redo log of every committed transaction to a remote, networked storage system on a secondary site (see figure below). Several vendors offer this storage replication option. In some of these SAP-certified solutions, the SAP HANA transaction at the primary site is completed only when the SAP HANA transaction log at the primary site is replicated in the backup site. This is known as synchronous storage replication and can occur only if the two sites are within 100 kilometers of each other with a fraction of a millisecond round-trip latency.
If a full system failover is needed, the system administrator attaches a passive system to the secondary storage and ensures that there is no data corruption from both systems writing to the same storage. The SAP HANA system is then restarted to complete the restore process.
This mechanism has an advantage over the backup-restore mechanism because RPO is much lower in this case, although there is an additional requirement in terms of network bandwidth and decreased latency between the primary and secondary storage sites. This option has medium costs associated with it with near-zero RPO (zero RPO for synchronous replication) and medium RTO.
The disadvantage of storage replication is that if there is any corruption to persistence for any reason, the corruption is also replicated.
SAP HANA Host Auto-Failover (High Availability)
In this scenario, an existing single-node or scale-out setup is extended by additional server nodes called standby nodes. Although SAP HANA supports multiple standby nodes, it’s typical for only one additional node to be used. This standby server can take over in case one or more regular hosts become unavailable.
If one host fails, the standby host automatically takes over by gaining access to the data and log volumes of the failed host. Thus, the standby server needs access to all the database volumes, which is accomplished by a shared network storage server. The following figure shows a configuration for host auto-failover.
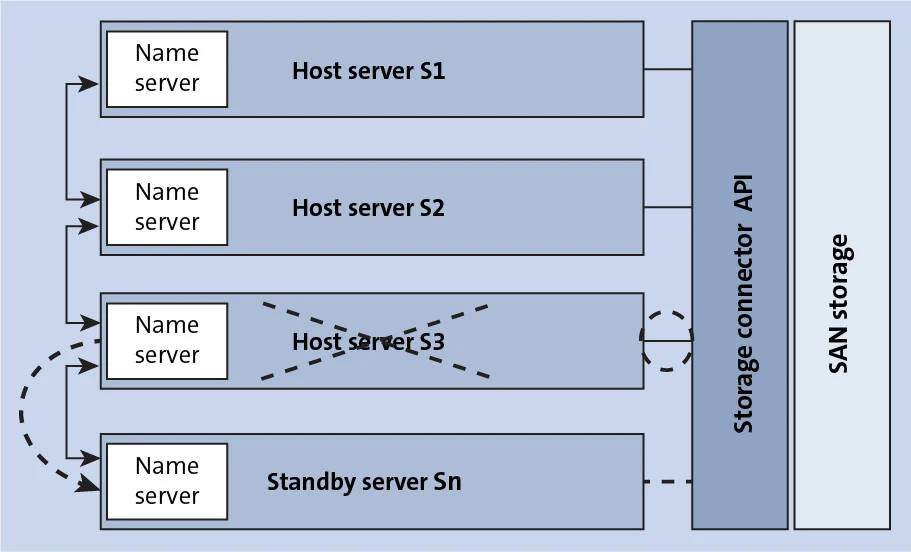
The standby host is connected to this storage either through a distributed file system or by using vendor-specific solutions via the SAP storage connector API to dynamically detach and mount networked storage when the failure occurs.
Note that all services are moved to the standby server when the failover happens at the host server level. This failover happens automatically without any external cluster manager but doesn’t happen in the case of a single service failure.
There are some useful techniques to maintain data consistency and to ensure that the primary and standby hosts aren’t active at the same time and thus avoid allowing the recovered host and the standby servers to write to the data in parallel.
This option for HA has medium associated costs, zero RPO on committed transactions while in-flight transactions are lost, and medium RTO. RTO depends on the database size as the data needs to be loaded into memory. It’s a good option for scale-out systems as it keeps the costs down, and only one additional server (or VM) is required.
SAP HANA System Replication (High Availability/Disaster Recovery)
System replication uses the N + N mode. For every SAP HANA server with N nodes, there is another similar server with the same number of nodes as the secondary. In this setup, the two databases (primary and secondary) can be located close to each other. Alternatively, the secondary database can be at a remote location as a DR option as well, but a reliable link is required between the two sites. The configuration is shown below.
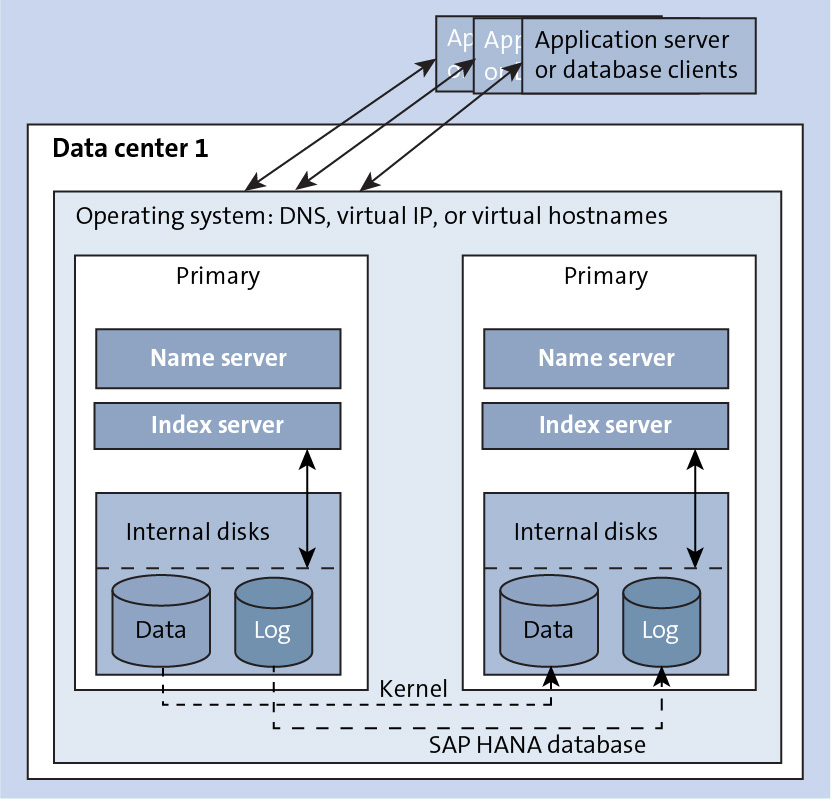
This option employs the live replication mode. In this mode, the services of the secondary SAP HANA system constantly communicate with that of the primary system, and all the data and logs of every transaction from the primary system are replicated and typically stored in the database in the secondary system with the same system identifier (SID) and instance number. The data commit in the primary system even can be set up to be complete only on persisting this replication log in the secondary system.
There are a few options for how the data commit in the primary system can be set up depending on the log transmission and its writing to memory or persisting in storage to be synchronous or asynchronous. The replication modes are as follows:
- Synchronous: The secondary system sends an acknowledgment only after saving/persisting the data. This mode can run with a full sync option, which means that log write is successful when the log buffer has been written to the log file of the primary and the secondary instance. In addition, when the secondary system is disconnected (e.g., because of network failure), the primary system suspends transaction processing until the connection to the secondary system is reestablished. No data loss occurs in this scenario.
- Synchronous in-memory: The secondary system sends an acknowledgement as soon as it receives the data.
- Asynchronous: The primary system doesn’t wait for acknowledgement from the secondary system.
Note that synchronous modes are very much dependent on latency. Thus, high latency can seriously impact the performance and therefore should be used only when both databases are connected by low-latency networking.
There are two operation modes for system replication:
Delta Data Shipping
To avoid ever-growing logs, data snapshots are shared from the primary system to the secondary system at regular intervals. In addition, the primary system shares status information about the column tables stored in the main memory. The secondary system loads these tables into memory. This is called a preload. In the case of a failure, the cluster manager initiates live replication mode in full operation for the secondary server. The secondary system, with preloaded column tables, will only load the row tables and replay the last transaction logs to operate as the primary system.
Log Replay
The secondary system can instantly replay the log, thereby diminishing the delay in takeover to near zero.
The other consideration in this option is about the connections from the database client that are configured to reach the primary server. There are two options for diverting these connections to the secondary server after the failover. SAP NetWeaver connects to SAP HANA via the Database Shared Library (DBSL). One option is to use a virtual IP address to access the database host and the database instance on that host. Alternatively, the Domain Names Service (DNS) can offer virtual hostnames. This HA option has the highest cost but the lowest RTO and RPO.
The main difference between delta shipping and log replay is internal mechanics: Delta shipping sends logs to be saved to disk (not applied to data) and at regular intervals sends deltas of all block changes that happened since the last delta. For recovery, logs need to be replayed. The advantage is the low memory consumption; the secondary system can be used for nonproduction (QA).
In log replay, this is different; all logs are applied to the secondary database, thus requiring reduced network traffic between the systems and reducing RTO. However, as the memory requirement is greater, using the secondary system for nonproduction becomes difficult.
The logreplay_readaccess option enables SAP HANA system replication to support read-only access on the secondary system. This option is based on the continuous log replay feature and inherits its characteristics. Because it enables fast take-overs, the need for bandwidth is much reduced. For DR, the secondary system or storage must be in a remote location. For SAP HANA 2.0, this option has received a boost with faster initial load from primary to secondary systems through multiple streaming (up to 32 streams). It also has faster disk to memory with up to 32 threads in parallel load and can have continuous access to business data while the primary system is in restart mode.
An interesting load-balance feature SAP HANA 2.0 brings to the fore is the ability to enable read-intensive operations (say, from an operational report or an analytics dashboard) between a primary and secondary instance of SAP HANA with the active/ active-read-enabled mode. There is also now a consolidated log backup file to make it easier for third-party tools to back up data.
Conclusion
Data failures can cause you significant headaches. With SAP HANA, recovering data from a savepoint and beyond is not just a dream; it is possible. The post above outlines a plethora of data recovery options you can elect to implement on your database. It is important to know these not only for your day-to-day tasks but also for doing well on exams such as the SAP HANA Application Associate Certification exam.
All of these options for HA/DR have their advantages and disadvantages, so it’s best to sit down with your team and discuss which makes the most sense for your organization. If you need more information, check out SAP Note 2057595 (FAQ: SAP HANA High Availability). Further details on operations mode and the constraints can be found in the SAP HANA Admin Guide under Availability & Scalability > Configuring SAP HANA System Replication.
Editor’s note: This post has been adapted from a section of the book SAP S/4HANA: An Introduction by Devraj Bardhan, Axel Baumgartl, Madalina Dascalescu, Mark Dudgeon, Piotr Górecki, Asidhara Lahiri, Richard Maund, Bert Meijerink, and Andrew Worsley-Tonks. They are are a multinational author team working for IBM, SAP, and Accenture. They have
been working with SAP S/4HANA since its first release.
This post was originally published 4/2020 and updated 3/2025.



Comments