
SAP HANA is an in-memory database and is only supported on certified hardware. By requiring certified hardware, SAP is making sure that core-to-memory ratio is respected.
The core-to-memory ratio is the key to guaranteeing optimal performance. Certified hardware unfortunately doesn’t come cheap. The in-memory and column store capabilities of SAP HANA enable access to data at an incredible speed. The question is, do you need fast access to all data, all the time? The cost of keeping all the data in memory may not be justifiable. Most users find that slower access to old or rarely used data is acceptable.
What about Data Archiving?: Data archiving has been around for some time and is used by many companies. If data archiving is not in place, it should be considered a project by itself. Archiving projects should not be underestimated. It’s up to business to decide what data may be archived and what may not.
There are several solutions that can be used to minimize the data footprint, limiting the required memory:
- Persistent memory
- SAP HANA native storage extension
- SAP HANA extension node
- SAP HANA dynamic tiering
- SAP IQ
- Hadoop
SAP HANA Data Warehousing Foundation: The SAP HANA data warehousing foundation is a series of tools for large-scale SAP HANA systems that supports data management and distribution within the SAP HANA landscape. Large-scale SAP HANA systems consist of hot, warm, and cold data. Keeping all that data in-memory is or too expensive or just impossible due to hardware limitations. The SAP HANA data warehousing foundation can be used to optimize the memory footprint by combining solutions such as SAP HANA dynamic tiering, SAP IQ, or Hadoop with SAP HANA. The Data Lifecycle Manager of SAP HANA data warehousing foundation provides an SAP HANA XS-based tool to relocate data from hot or warm to cold or vice versa. For this purpose, Data Lifecycle Manager lets SAP HANA administrators model aging rules on persistence objects.
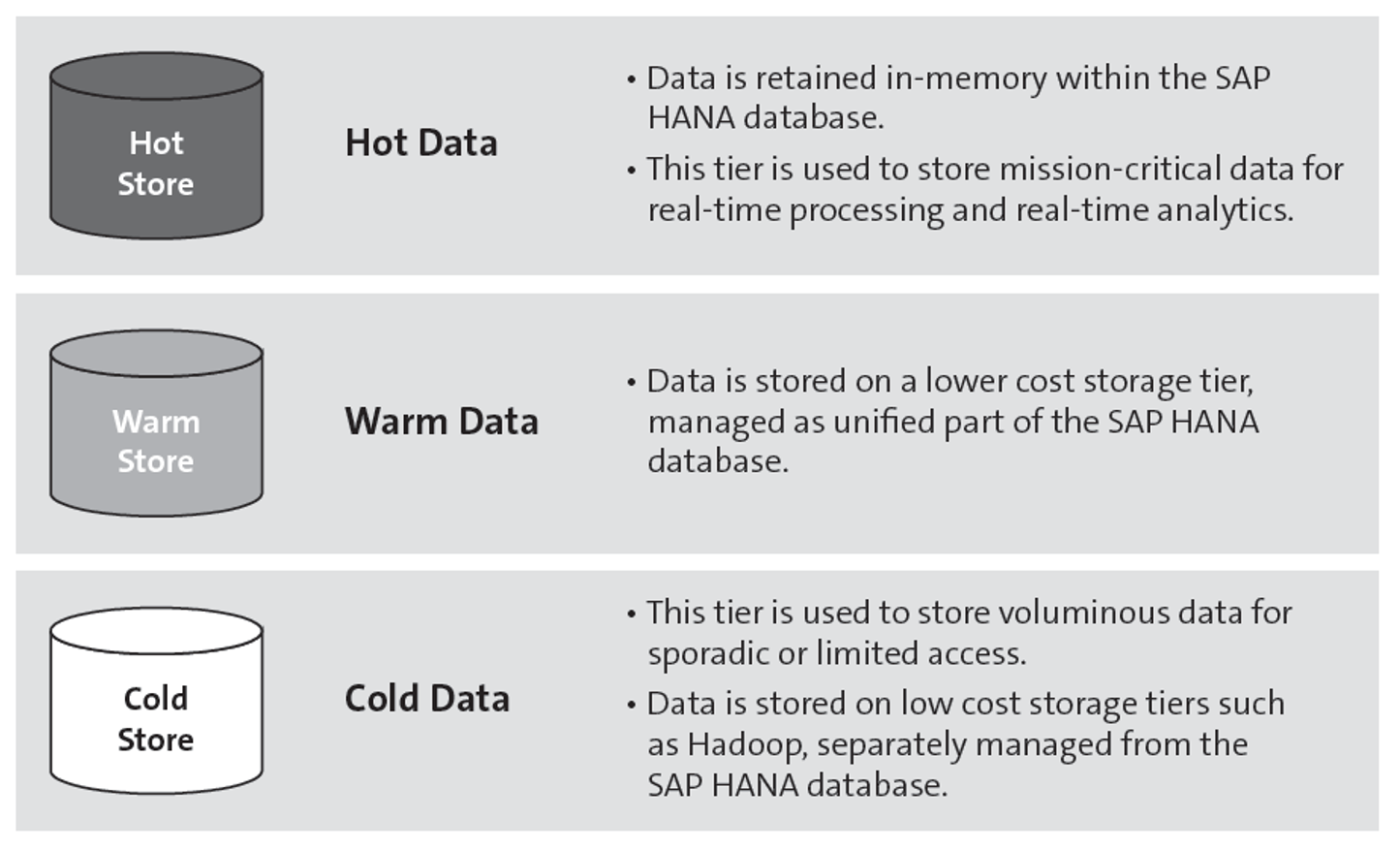
Aging is the process of becoming older—something all of us have to undergo, like it or not. Data is also subject to aging. As time goes by, data will be less and less accessed or even updated. Data aging is a data management concept to reduce the SAP HANA memory footprint based on the data aging framework. Data aging is available in SAP ERP on SAP HANA and in SAP S/4HANA and can move large amounts of data from hot to warm storage to free working memory for younger data. Data ages from operationally relevant or hot data to data no longer accessed during normal operation or cold data. The data temperature can be used to partition tables to optimize resource consumption and performance and to move data between hot, warm, and cold partitions. Hot data is stored in memory, warm data is stored primarily on disk, and cold data is stored outside of the SAP HANA system. Data can be divided according to age and the number of times it is accessed (see figure below):
- Hot data is data considered mission critical for processing and analytics. This data should be stored in memory within SAP HANA to guarantee performance. Hot data is kept in the hot store, which consists of the standard dynamic random-access memory (DRAM) and which can be extended with persistent memory.
- Warm data is accessed less frequently. This data can be stored on a lower-cost storage tier. As the data is still accessed, it should be managed as part of the SAP HANA database. Solutions such as SAP HANA native storage extension, SAP HANA extension node, and SAP HANA dynamic tiering can be considered.
- Cold data is accessed occasionally. Cold data can be stored in SAP IQ and Hadoop on commodity hardware or in the cloud in Azure Data Lake and SAP Big Data Services. The data is stored outside the SAP HANA system. Although it is no longer part of the SAP HANA database, it can still be accessed at any time.
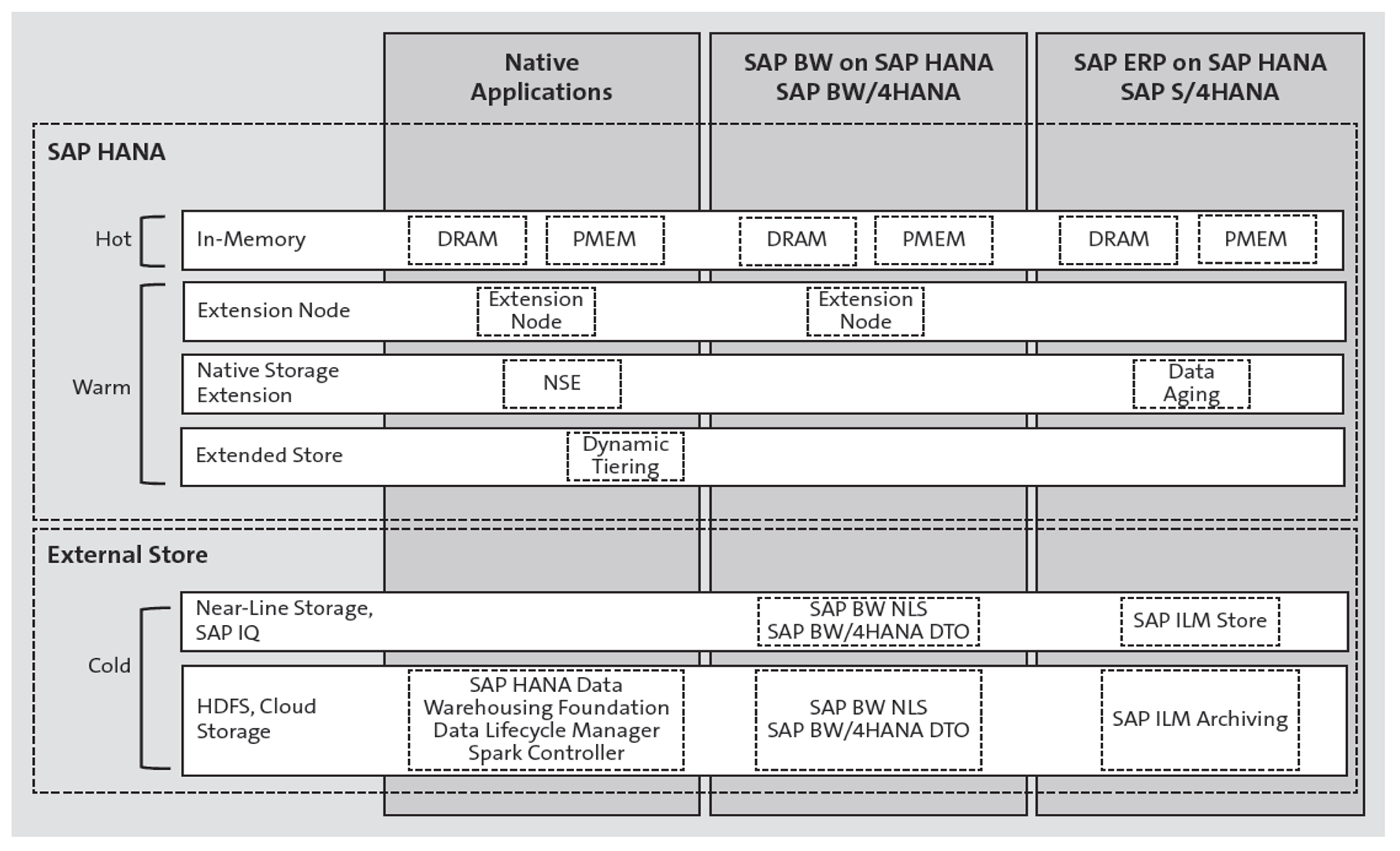
SAP has different data tiering options for hot, warm, and cold data, which can be used in combination with SAP HANA (see next figure):
- Hot data is stored in memory. For performance reasons, SAP HANA loads the column tables into memory. Standard DRAM is still volatile, meaning if the SAP HANA instance is restarted, whether for maintenance or after a failure, all data needs to be reloaded into memory. This can take up to several hours on large systems. This is where persistent memory comes into play. It has a lower TCO and larger configurations are possible then with DRAM. Data in persistent memory maintains its state after a system shutdown. This reduces database startup time enormously as data no longer needs to be loaded from disk into memory.
- Warm data is data that is still accessed, although infrequently. It’s between hot and cold data: not accessed enough to load it in main memory but accessed too much to be moved outside of the SAP HANA system to alternative storage locations. Warm data is handled differently according to the applications in use:
- SAP HANA native storage extension is a warm data store in SAP HANA. It allows the applications to load less-frequently accessed data without fully loading it into memory. It combines in-memory storage with solid state or flash drives to improve the cost-to-performance ratio. With SAP HANA native storage extension, pages can be loaded instead of columns, reducing the memory footprint. Page attributes allows table columns to be loaded by page from the persistency layer into memory without requiring the entire table to be loaded into memory. SAP HANA native storage extension is used by SAP S/4HANA and the SAP Business Suite powered by SAP HANA.
- An extension node is a dedicated SAP HANA in-memory node for warm data processing. It can be added to an existing SAP HANA database to scale out at a lower cost. It can be used in combination with SAP HANA native applications and SAP BW. An extension node is basically an SAP HANA node with the same functionalities as any other SAP node. Memory and CPU requirements are more relaxed, meaning that they have an extended core-to-memory ratio. An extension node keeps the data on disk only loading it when needed. If memory is scare, the extension node will unload data from memory to disk based on a least recently used algorithm. As the extension node only contains warm data, which is modified less frequently, more data can be loaded into memory as the SAP HANA instance needs less memory for the workspace. Extension nodes need to be deployed on certified SAP HANA hardware. Commodity hardware cannot be used.
- Another option is SAP HANA dynamic tiering, an add-on to the SAP HANA database. SAP HANA dynamic tiering can be added to an existing SAP HANA database as an extension to create queries and load data into disk-based, column-based database tables called extended tables and multistore tables. SAP HANA dynamic tiering is only supported with SAP HANA native applications. It can be deployed on commodity hardware, making the storing of warm data less expensive.
- Cold data may be stored on the lowest-cost storage solution as long as it remains accessible to SAP HANA. The SAP HANA spark controller can be used to manage the cold data tier for native SAP HANA applications. The SAP BW near-line storage option can be used with SAP BW and SAP IQ.
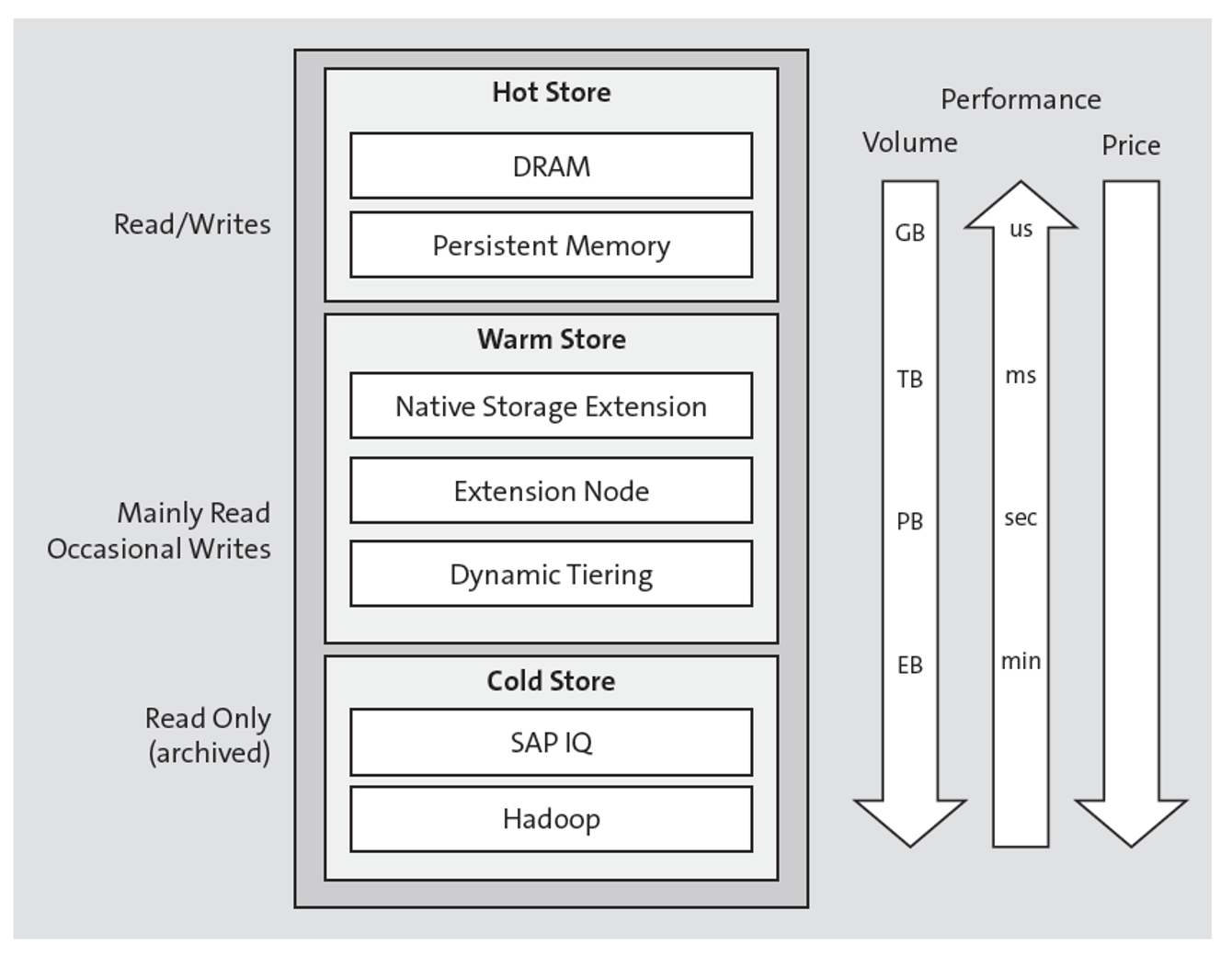
The final summarizes the data tiering options and categorizes them according to volume, performance, and cost.
Editor’s note: This post has been adapted from a section of the book SAP HANA 2.0 Administration by Mark Mergaerts and Bert Vanstechelman.



Comments