
A technical conversion is a combination of a release upgrade from SAP ERP to SAP S/4HANA and a database migration from the current database system to SAP HANA.
This is a large and complex process that runs for several days. Proper planning is essential for several reasons. First, you must become familiar with the behavior of the conversion in the present environment: you must learn how long the different key phases of the conversion take, especially ones such as downtime that are time-critical.
You must learn whether the servers are able to cope with the load caused by the conversion: Is their normal capacity sufficient, or do they need some extra oomph in the form of additional CPU power, more memory, or faster storage? Is that extra capacity even there? You must discover the hot spots in the process where problems occur or specialists need to be brought in to carry out certain activities. By the time you get to the conversion of the production systems, all these questions must have as precise an answer as is reasonably possible. Surprises may still happen when you convert production, but they should be true surprises, not avoidable mishaps resulting from a lack of knowledge and preparedness.
A first subject to address is this: How many conversions should you do, and on what type of system? Assuming a traditional three-system landscape with development, quality assurance (QA), and production, the answer is not three. Not just production but also development and QA should be seen as mission-critical systems. Prolonged unavailability of the development or QA system not only leads to unemployed developers, test users, and consultants, but also is a threat to the stability of the production environment—for instance, because it becomes very difficult to provide critical corrections in a reliable manner. The elaborate and time-consuming process of testing and fine-tuning the conversion shouldn’t run in these core systems; you need a proper test environment: a sandbox.
Conversion of a Sandbox System
There is a price tag for setting up such a sandbox. You need a server to run the SAP ERP instance, as well as the current, non-SAP HANA database. You may need a database server for SAP HANA. (If the SAP HANA appliance has already been delivered, then you can use it for the test conversion and erase the database afterwards.) You need time and personnel to build the system. All that is true, but the investment is necessary nonetheless; the payback will be an efficient conversion within your budget and on time.
Technically, the sandbox environment should meet two conditions:
- The database should be the same size (or as close as possible to the same size) as the production system. Although the conversion time is not directly proportional to the data volume, the size does have a significant impact on the runtime of several key phases. Creating the sandbox as a recent copy of the production system is the best solution. A copy of the development system is not suitable because these systems typically have small databases containing little data.
- Ideally, the hardware of the sandbox server should have a capacity resembling that of the production machines. It may be slower (in which case the timing information gathered during the test migration may be treated as a worst-case estimate), but it shouldn’t be faster. It may sound absurd to have the sandbox running on faster hardware than the real production system, but this isn’t illogical. If, for example, the production servers are relatively old and you set up a latest-and greatest machine for the sandbox, or rent one in the cloud, then there is a real chance that the sandbox conversion will run faster than what will be achievable in production.
Our preferred scenario is to run two test conversions in the sandbox. The purpose of the first run is to get to know the behavior of the process, solve all errors, and create documentation. Thoroughness, not speed, is the main objective here. With the second run, you can then focus on the runtime and look for opportunities for performance optimization. Running two tests is a luxury you won’t always be permitted: if only one test is possible, then give priority to learning and documenting the process, combining this with some basic optimization. You can then use the conversion of the QA system, which almost always has a (near-) production-size database, for further performance tuning.
Conversion of the Development System
With the experience you gained in the test conversion or conversions, you should be able to tackle the core systems with confidence. For the development system, there is a caveat, though. By nature, these systems tend to be “dirtier” than QA and production systems: they contain ongoing and not yet fully tested development work, and often also the flotsam and jetsam of old and discarded code, test objects, or things a developer once began working on but never quite finished. As a result, there are far more objects here than in QA or production that can cause trouble during the conversion.
The test conversion can be helpful here too, because it will enable you to distinguish relevant objects (the ones you encountered in the test conversion, such as during modification adjustment) from irrelevant ones. Of course, the decision about what objects are irrelevant and can be ignored is the developer’s, not yours, to make.
Conversion of the QA system
QA systems normally have a database that resembles that of production, both in size (most QA systems are more or less recent copies of production) and in content (representative business data and a much cleaner repository than that of the development system). This makes the QA conversion the dress rehearsal for the real thing: production.
We have known projects (for upgrades, but the same might happen with migrations) in which the QA system wasn’t converted at all. Instead, the existing system was scrapped, and after the production conversion a brand-new QA was created using a system copy of production. If that’s what management decides, then you should live with that, but only if you have had the possibility to thoroughly test the conversion in the sandbox environment—at least once, but much better twice. We probably don’t need to say this, but you must never—we repeat, never—accept a scenario in which the first production-like system to be converted is production itself. To reassure you: this has never happened to us, and our customers have always been sensible.
Conversion of the Production System
In an ideal world, converting the production system is a piece of cake. The procedure is well documented from start to finish, the quirks are known and can be dealt with, and you know exactly what will happen and when. Even in a nonideal world, this is how things sometimes go; we have indeed known upgrades and conversions in which we could almost switch off our brains and do what the book (i.e., our documentation) said, and the whole thing ran like clockwork. However, forewarned is forearmed, and you shouldn’t expect things always to go so smoothly simply because you’re well prepared. In various ways, production systems are different from their nonproduction companions, and all of these differences can cause unexpected troubles. Here are a few possible pitfalls:
Uptime Work
As you’ll read several times later, by uptime, we mean that the system is in normal productive use and that end users are doing their normal work in parallel with the conversion process. That’s all well and good, but what does normal productive use really mean? In the sandbox system, there will be extremely little, if any, other activity. Development systems are rarely under heavy load, and with the likelihood of a development freeze being in place, that load may even be smaller than usual. This will probably also impact the QA system, so not much might be happening there either. In production, however, real work is being done, and that work can put a heavy strain on the resources of the server. You might suddenly discover that things aren’t going quite as quickly as the timing data you collected during the earlier conversion indicates.
Archiving Database logs
Archiving database logs is a bottleneck we’ve encountered several times. This is what happens: the policy for database log backups holds up well with normal system activity but turns out to be unable to cope with the extra logging volume caused by the large-scale database changes made by the conversion. The result can be, for instance, an overflow of the database logfile system, eventually causing the system to hang.
Interfaces
Interfaces are another concern. The sandbox system is probably a copy of the production system, including the configured interfaces, but in the sandbox those interfaces won’t be operational. Stopping and restarting interfaces are among the key manual activities during the conversion; in the sandbox, this may be an entirely academic exercise. The development and QA systems will probably be somewhat better, but even these systems are rarely fully comparable to the real intersystem activities, like SAP BW loads, seen in production. Difficulties with stopping interfaces are especially problematic because, unlike the first two issues, they occur during the planned downtime and thus are very much on the critical path.
The figure below shows a schema of the complete conversion process, with a timeline running from the top to the bottom. The size of the boxes representing the conversion phases are not exactly proportional to the relative length of these phases, but they give an indication.
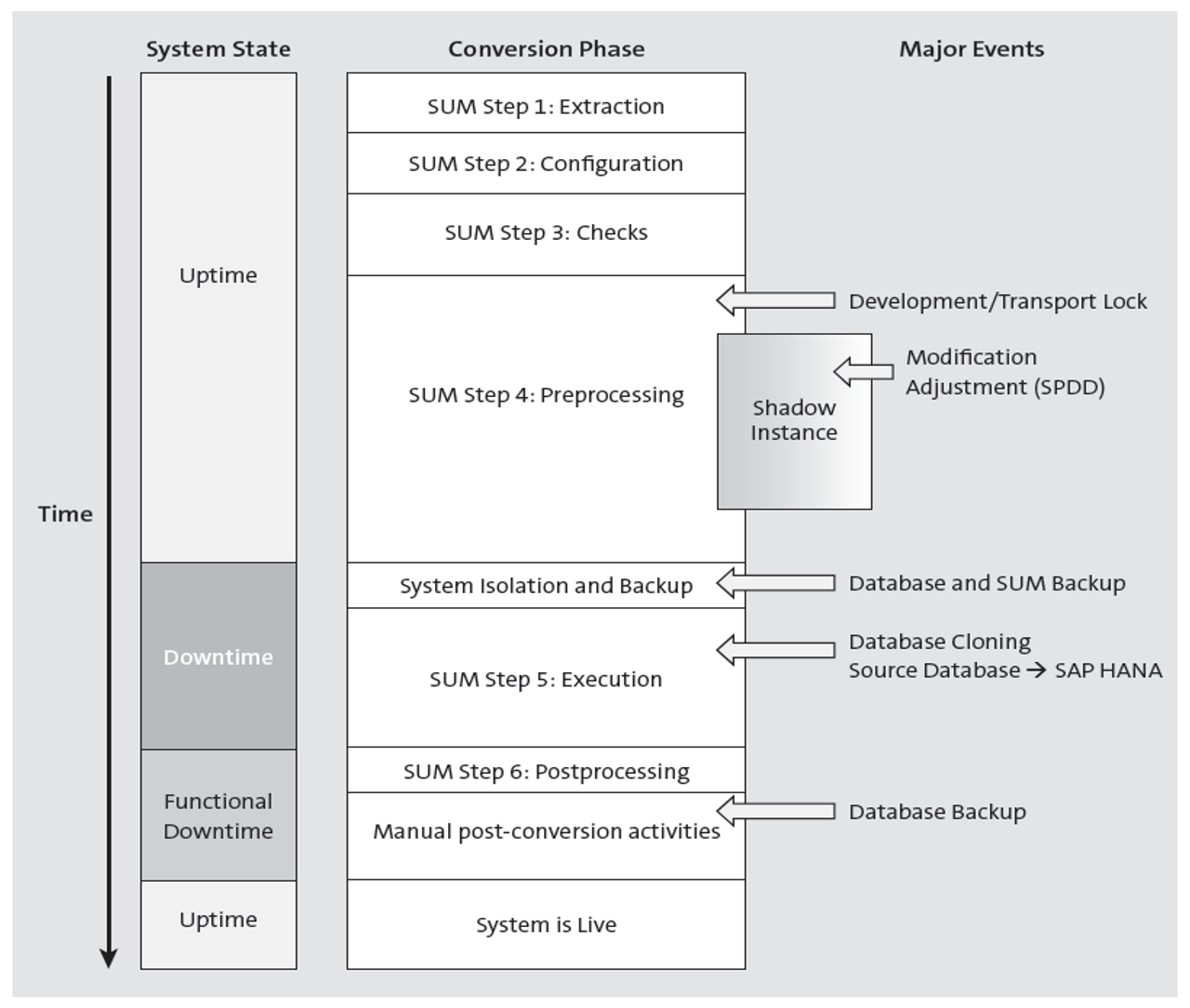
The system state portion on the left shows the availability of the system. The first part of the conversion runs in parallel with other activities in the system. At a certain point, these uptime activities will come to an end, and you’re then expected to isolate the system (e.g., by locking users and stopping interfaces with external systems). This marks the beginning of downtime, during which the system is accessible only to SUM.
For the last phase of SUM, the system is restarted with its normal configuration. It’s thus technically available, but not yet in a state that permits normal productive usage. During this time, only the technical conversion team and, at a later stage, the functional test users have access to the system, a state we denote as functional downtime. The process itself does not end with the SUM but also includes a series of manual postconversion activities to further prepare the system. If the tests are positive and the go-ahead is given for opening the converted system for production work, the earlier steps to isolate the system are undone (users are unlocked, interfaces restarted, etc.) and the system goes live.
The right-hand side of the above figure lists some major events that occur during the conversion. Less than halfway through the initial uptime part, SUM locks the system against further development and transports. This means that though still operational, it’s no longer possible to make changes to repository objects such as programs or dictionary structures. Shortly afterwards, SUM starts the shadow instance, a parallel dialog instance that is already running on SAP S/4HANA and uses the SAP HANA database. This instance is used for several key activities (most importantly, the activation of the new dictionary), which otherwise would have to be deferred until downtime. The shadow instance runs alongside the productive dialog instance on the primary application server.
At the system isolation point, you must back up both the source and the new SAP HANA database, or at least be able to guarantee that the databases can be recovered to their current state. You must also back up the SUM directory; this is necessary if for some reason the conversion has to be aborted and is restarted later at the downtime point.
The most important action during the SUM downtime is copying (cloning) the complete source database to SAP HANA (previously only the part necessary to operate the shadow instance had been copied to the SAP HANA side). As we’ll discuss, SUM gives you the opportunity to tune the cloning process several times with different settings—at least during test conversions, though not in the production conversion.
At the end of the SUM process, you must back up the SAP HANA database (not the source database, which basically has become a dead object now). This is useful in case the system is damaged by a post-conversion activity (e.g., because of an inconsistent transport queue) or by a major error during testing (e.g., accidental deletion of business data).
If everything goes according to plan and the system becomes productive again, then your work still isn’t done: during its first days, the system must be closely monitored, and its configuration may need to be adapted.
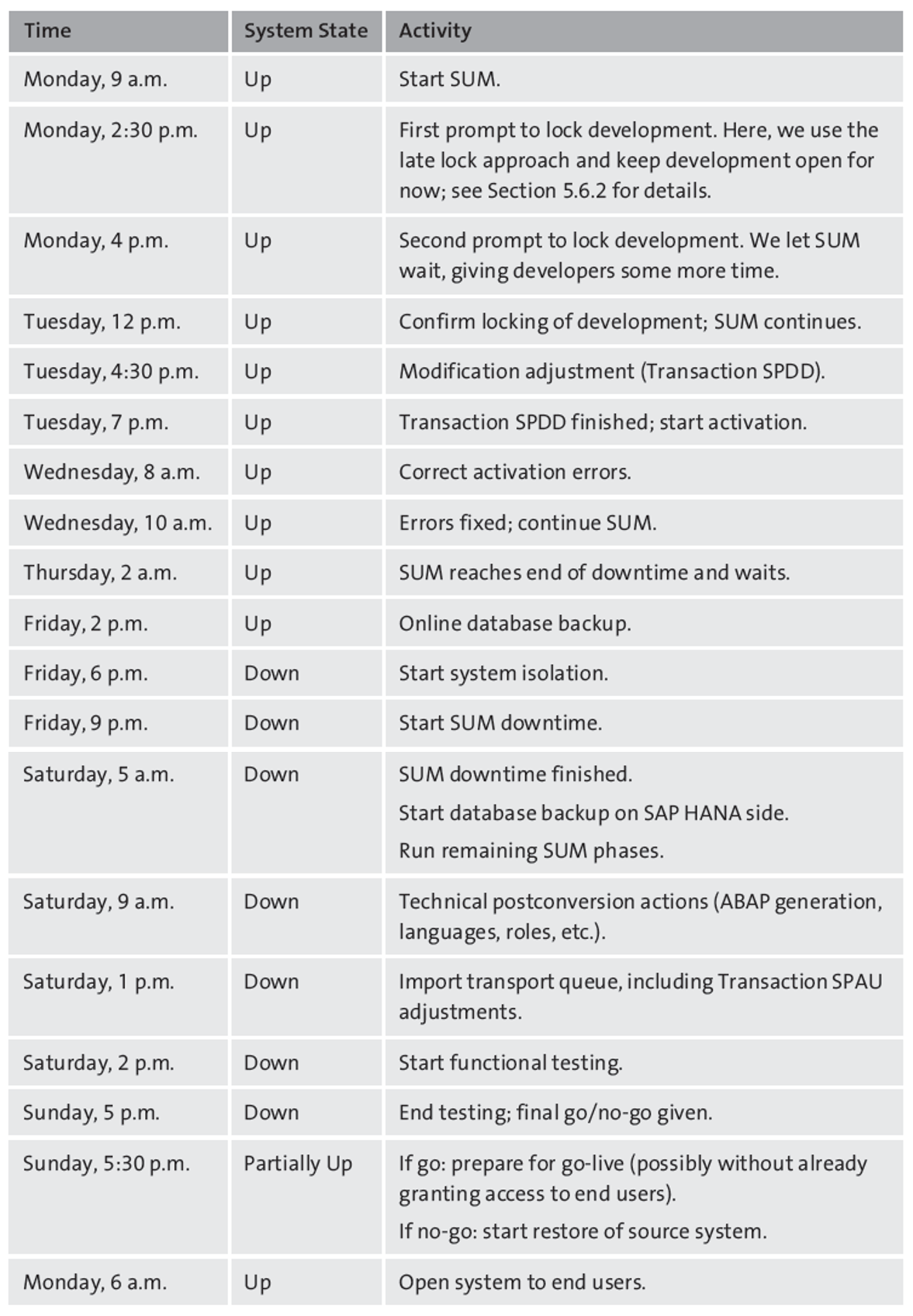
To assist you with setting up a workable schedule for the production conversion, we’ll provide a practical example of how to time the technical conversion process. The schedule in the table below is comfortable in the sense that there is a large safety margin, both for the uptime part of the SUM and for the activities during the downtime weekend. Note that this is just an indicative schedule, although it comes pretty close to what we do in practice: you must plan your activities for the production system in light of what you’ve learned from earlier conversions and the specific requirements or constraints of the environment you are working in.
Editor’s note: This post has been adapted from a section of the book SAP S/4HANA System Conversion Guide by Mark Mergaerts and Bert Vanstechelman.



Comments