
As Clive Humby once said, “Data is the new oil.” For those working with big data, there is tremendous pressure to capture the internet of things (IoT) data from sensors in a more efficient and effective way.
With the advent of Industry 4.0, sensors, and interconnected devices, new challenges have appeared for data scientists. Their main challenge is to ingest and utilize both homogeneous (same kind) and heterogeneous (different kind) IoT data from sensor devices. And considering Industry 4.0 is in full swing, every day there are new devices with new sensor parameters to monitor in order to optimally run things.
Big Data Challenges
Ingesting and utilizing homogeneous and heterogeneous data is just one challenge facing IoT practitioners. Other data volume storage issues include:
Data Volume
While it’s necessary to store all big data from IoT devices so that data is not lost, we don’t want to spend resources holding unnecessary data that may not require analysis.
Omni-channel Source Data
When it comes to the capture of multiple sources of data, we may run into some issues due to different device architectures. For example, legacy devices may be storing data in one type of file format on a relational database, while newer devices may collect data in different formats. Both forms will need to be managed to make the most of all your data.
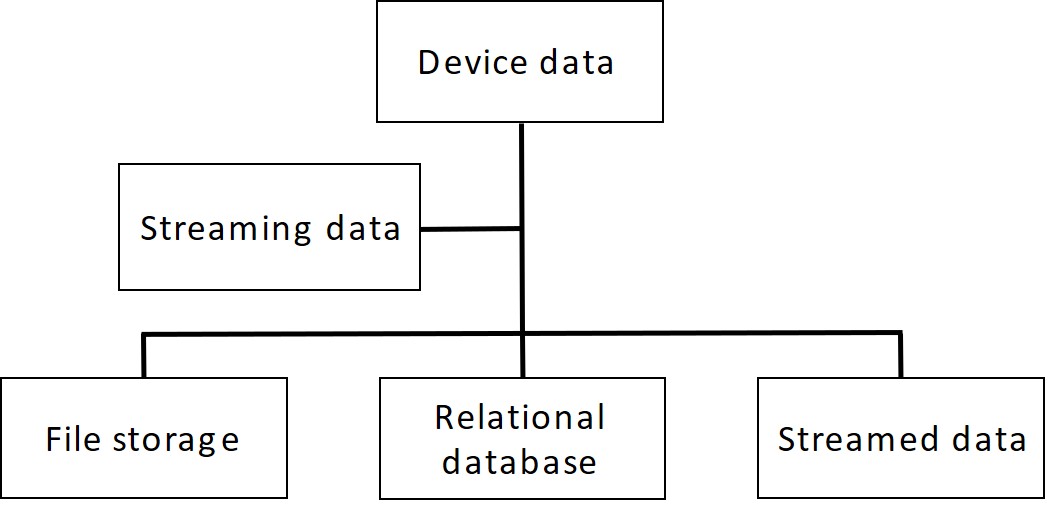
Heterogeneous Data
There are different kinds of smart sensor devices. These may have the same parameters in theory, but due to different reporting and measuring standards, report that data back in different units (such as pounds in the US and grams in the EU). This heterogeneous data causes challenges for reporting; they will need to be converted to a single reporting metric.
SAP’s Solution: SAP HANA
To cater to the needs of sensor data capture without the loss of any data, we need to have a big data platform which can store it. If this is done, the data can be used wisely both in terms of storage and analytical results—hopefully, in real time. This will help businesses make appropriate decisions.
For those who use SAP, the SAP HANA in-memory database serves both these needs. It acts as both a proper and optimized storage mechanism of IoT data and provides real-time monitoring of devices, all while being a cost-effective option for businesses.
The benefit of moving data to the memory layer of SAP HANA is that we can store data continuously without having any index, and utilize multiple partitions so data can be inserted without blocking any write operations. The partitioning mechanism must be done based on the data quality and type of data which is being received from the streaming layer.
Benefits of Clean Big Data
By importing clean data into SAP HANA, you benefit a handful of ways. Firstly, cleansed data ensures the highest return in terms of usage and value. Omni-channel data can be managed seamlessly which provides the enterprise with an opportunity to carry out successful analysis and predict a device’s output in the future.
Furthermore, having a clean and properly maintained database can help business enterprises ensure that their sensors are used effectively. It can also use current and existing data to predict when a device might fail or need repair.
Using the compressing techniques like Apache Hadoop’s parquet formatting, which uses a snappy algorithm to compress the data, data becomes more homogeneous and reduces the amount of input and output.
Lastly, as we store data of the same type in each column in a binary format, we can use encoding better suited to the modern processors’ pipeline by making instruction branching more predictable.
How SAP HANA Solves Big Data Problems
SAP HANA works in tandem with both SAP and non-SAP tools to solve these big data problems. Let’s dive in.
Data Filtering
SAP HANA’s architecture allows the administrator to create multiple partitions that can be utilized in big data management. Depending on the parameters you define, you can filter your data into these partitions, based around types of sensors, regions, or units being used.
Compression
Data compression is a great way to reduce the amount of space your data takes up. Those who use Apache Hadoop may be familiar with the parquet and optimized row columnar (ORC) formats, which take up to 75-80% less space than data stored in row formats. In order to store data compressed in the parquet format with Hadoop, SAP HANA works in tandem with a tool called SAP Vora. Once data compression is performed and loaded into SAP HANA, querying will be faster due to the compression of data as it has less to scan.
Microservice Implementation
Before storing compressed data in SAP HANA, it makes sense to filter out repeated data. To do this you can utilize a Spring Boot application; it parallelizes the data to further reduce the load on an SAP HANA database.
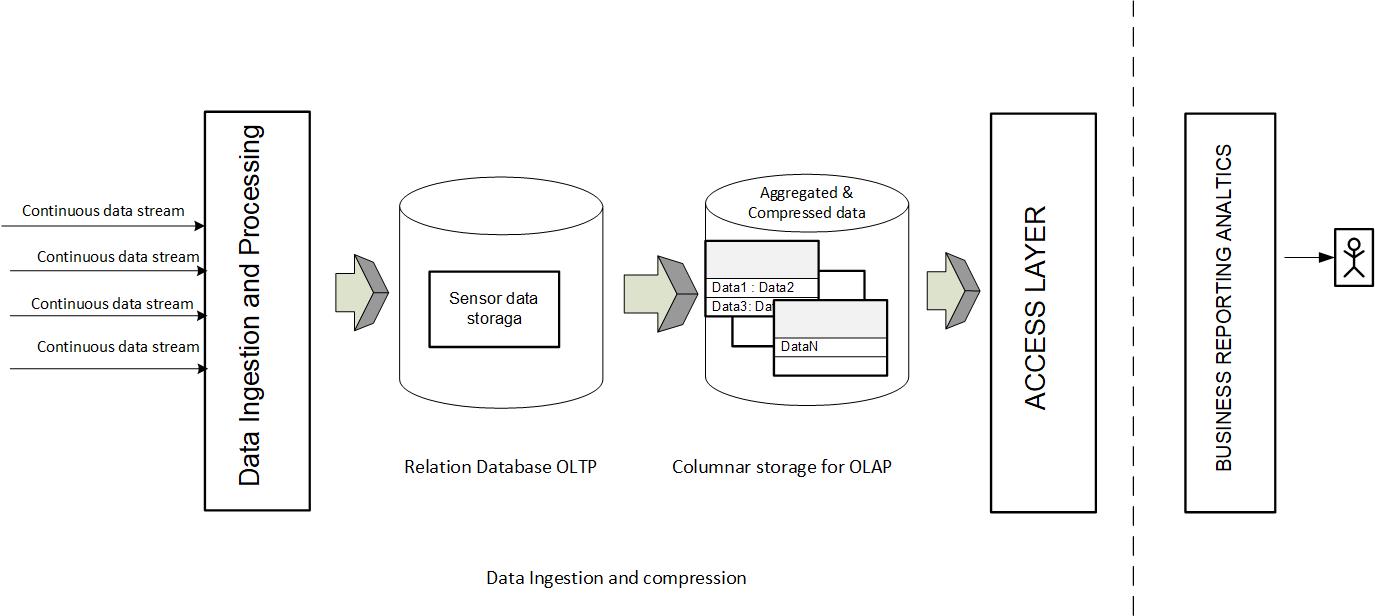
How to Import Data to SAP HANA
Now that we know how SAP HANA can help with IoT data storage, let’s take a look at how to get your data into an SAP HANA database. The whole path looks like this:
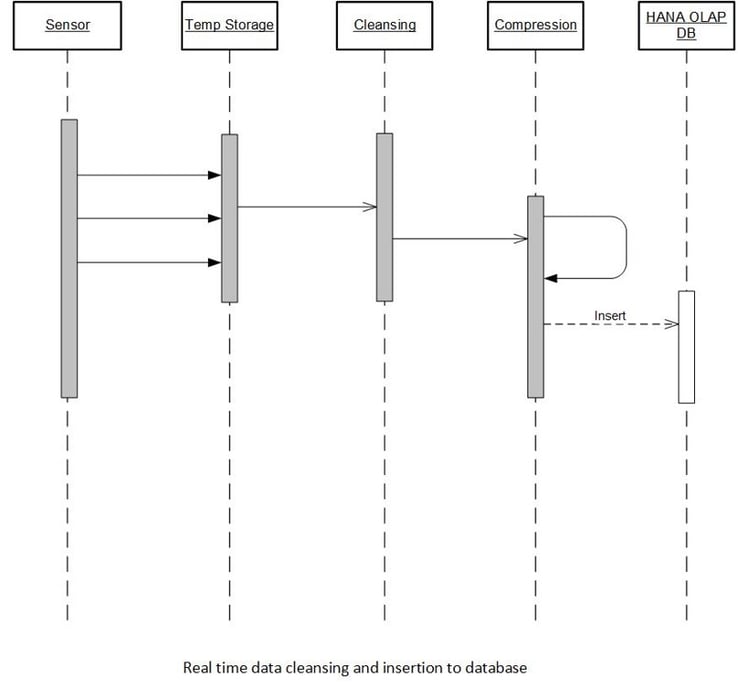
Data Ingestion
The first step of the data import process is ingesting the IoT data as-is into a landing container in the SAP HANA database. When performing the initial data load, do not worry about indexing the data; by forgoing this, the storage will be much faster. The goal is to store the raw data at the fastest rate.
Data Cleansing and Compression
Once this data is loaded, you can begin working on ways to cleanse your data and reduce the amount you’ll send on for analysis in the memory layer of SAP HANA. You can do this through filtering or data compression. Let’s first look at two different filtering options.
Data Volume-Based Filter
The IoT data streamed from a device arrives in temporary storage in the form of a packet. A data volume filter takes a look at the sizes of data in each row and filters out data that is larger or smaller than a pre-determined size.
Note: When filtering out data that is smaller than a pre-determined size, it’s important to look not only at the size of the packet, but also the contents. For example, if there are packets that are smaller in size than expected, this may indicate an instance where your sensor is not working properly or where signal loss is occurring. Fix the issue and then re-load the data so everything is imported. If it is still below the filter threshold, then it can be filtered out.
Time-Series-Based Filter
When working with time-related data, you may be able to reduce the amount of sensor data displayed by SAP HANA by using a time-series filter. This looks at both standard deviation (the time period during which the data remains valid—this may be short periods in the case of displacement, temperature, and humidity) and timeliness (freshness and consistency of data).
Let us try to understand via graphical approach how a time-series-based filter reduces the amount of data displayed. In Table-1 in the figure below, the first three rows all contain the same data despite being measured over a period of time. Similarly, the next four rows contain data different from the first three rows but identical to each other, and the final row contains yet even more different data.
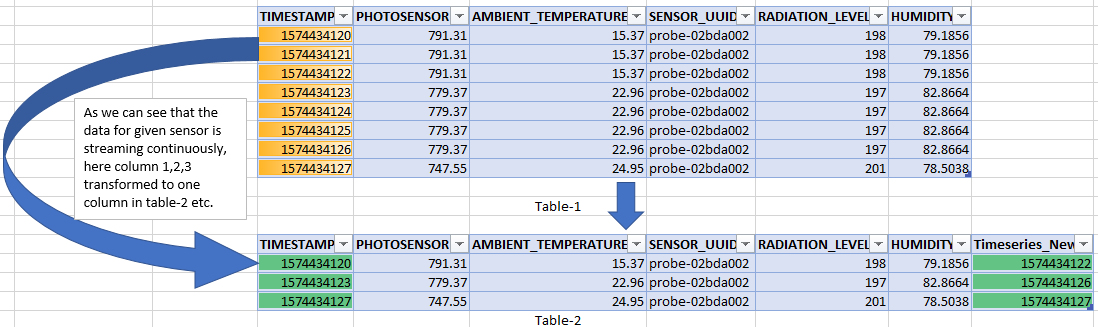
Note, however, how Table-2 has reduced the amount of rows being displayed. It does so by adding an additional “Timeseries_New” column, which displays the final timestamp of a series of identical data—in this way, you can see both the initial and final timestamp around the idle durations, both highlighted in green.
When IoT data is continuously streaming from sensors into temporary storage, you can see how removing repeated instances of data reduces the storage size, especially in cases where millions of records are being captured. Some have seen up to 40% reduction in data storage by using this approach.
Not only does this reduce data storage size, it can save you money, too. This is especially helpful when utilizing an SAP HANA cloud deployment where pricing is based on the amount of records inserted in a table.
Data Compression
Like filtering, data compression’s objective is storage size reduction. But instead of removing data sent on to SAP HANA, compression packs data into as little space as possible without losing any, also called ‘lossless’ data.
In order to compress, we’ll need to convert the cleansed data to a binary format which can be queried. As mentioned above, Apache Hadoop can be used to compress this data into a format such as ORC or parquet. Once this is done, the data will be ready to load into an SAP HANA database.
Using this approach, we can save space as well as optimize queries.
Data Synchronization
To hold or process a large volume of data without losing any, we need to have a microservice or isolation layer between data being ingested in the SAP HANA database and the IoT data already there. The microservices can be designed in any language like Python, Java, Groovy, or Kotlin, and can be in industrial formats like AVRO, parquet, ORC, JSON, CRV, etc. This layer will process the incoming data and create a batch operation to insert data into the memory layer of the SAP HANA database.
The benefit of moving data to the memory layer is that we can store data continuously without having any index, and utilize multiple partitions so data can be inserted without blocking any write operations. The partitioning mechanism must be done based on the data quality and type of data, which is being received from the streaming layer.
Accessing Data
Your data is now ready to be accessed by users in the SAP HANA database. Because the relevant, cleansed data is held in-memory, you’ll be able to get real-time information as you need it. And when you no longer need that data, it will be removed in regular intervals from this state and back down a layer, freeing up more memory space for future analysis.
Conclusion
IoT data storage is critical if you want to make the most of the information coming from sensor devices. In this blog post, you learned some of the challenges database administrators face when storing IoT data, and how SAP HANA and SAP Vora can achieve the data storage in a cost-effective way.
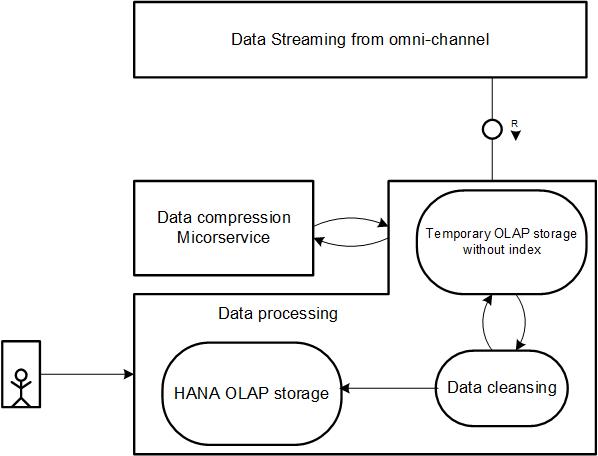
Below shows the full path, from the sensor data stream to access via SAP HANA.
Have you explored the SAP HANA database yet? If you want more information as to what it can do, click here for a primer on SAP HANA.



Comments