Most organizations employing SAP’s business warehousing solutions utilize flat files (such as the .CSV format) for uploading a variety of transactional business data into their systems.
Typically, the loaded data is further processed, cleansed and consumed in upstream systems with business logic.
The transactional data files are often prepared by functional business users, and human errors within the files can lead to erroneous data in the system, causing significant challenges. One type of error concerns special characters. The error is typically in the description fields due to word processing errors or copy-paste operations. The data load process rejects the special characters while processing the remainder of the data, causing the data request to appear as erroneous in the persistent staging area (PSA) layer or fail to process altogether.
This blog post explores a solution to address special characters by utilizing a combination of existing toolsets, and a bit of customization.
The Challenge
SAP Business Warehouse (SAP BW) offers an out-of-the-box solution for handling special characters using the standard transaction code RSKC. It allows users to maintain all special characters that are allowed within SAP BW (e.g. advanced DataStore Objects [DSOs], InfoCubes, etc.) This blog post addresses the challenge of processing flat files containing special characters before the data is loaded into the SAP BW system.
The main challenge is exploring and identifying a solution that meets the following criteria:
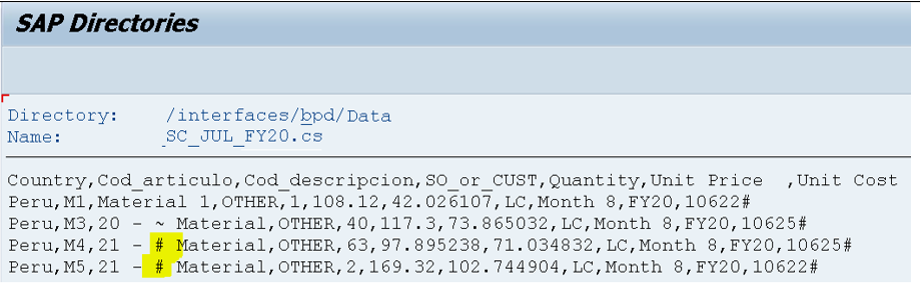
- Allow business transaction data in the flat file that contains special characters to be processed seamlessly into SAP BW layers. All special characters appear as “#” when flat files in AL11 folders are viewed or browsed, as shown in the figure below.
- Optionally allow special characters to be replaced with a configurable replacement.
Solution
Fortunately, SAP provides a rich framework of toolsets within the SAP BW system that can be leveraged to build a robust solution for a seamless user experience. This toolset includes InfoPackages with ABAP routines, and transformations with START/END routines where ABAP code can be deployed to access most objects within the System (InfoObjects, standard and custom tables, etc.)
Assumptions
- Flat files are available for processing in an AL11 directory at a defined location.
- This solution has been developed and deployed on the SAP BW system with the specifications listed below, but is also applicable to SAP BW/4HANA systems.

Code Page Setting in InfoPackage
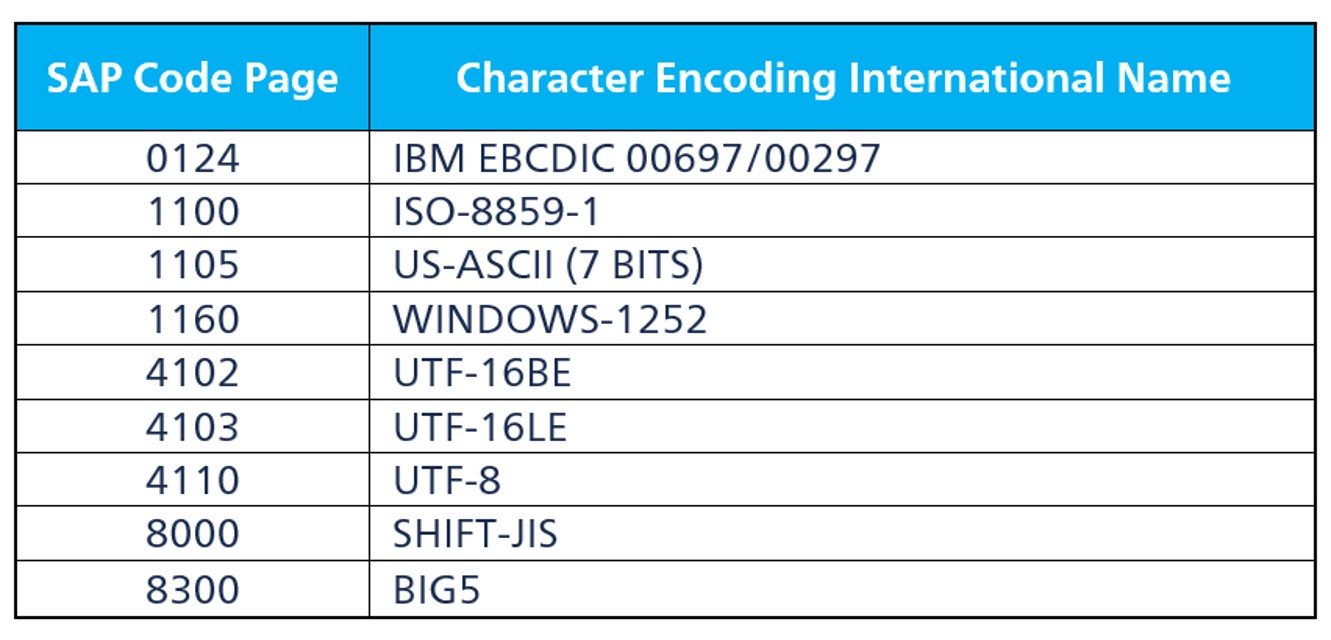
The character encoding is a coded character set for which a unique number has been assigned to each character. It reflects the way the coded character set is mapped to bytes for manipulation in a computer. There are many character encoding sets, for example, UTF-8, UTF-16, and UTF-32. In the SAP world, character encoding is named with code page which is a four-digit number. Some examples are listed in the table below. Algorithms associated with the code page are used to interpret incoming datasets in the flat file. The figure below shows the code page setting options in the InfoPackage, which offers two main options to process flat files.
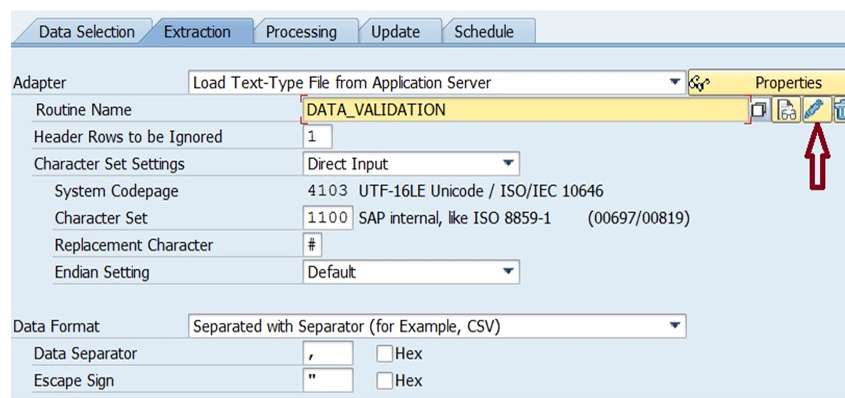
The first is to load text-type files from the application server. You’ll need to configure a routine to process the flat files. To do this in SAP BW, refer to the first figure below. To do this in SAP BW/4HANA, refer to the second figure.
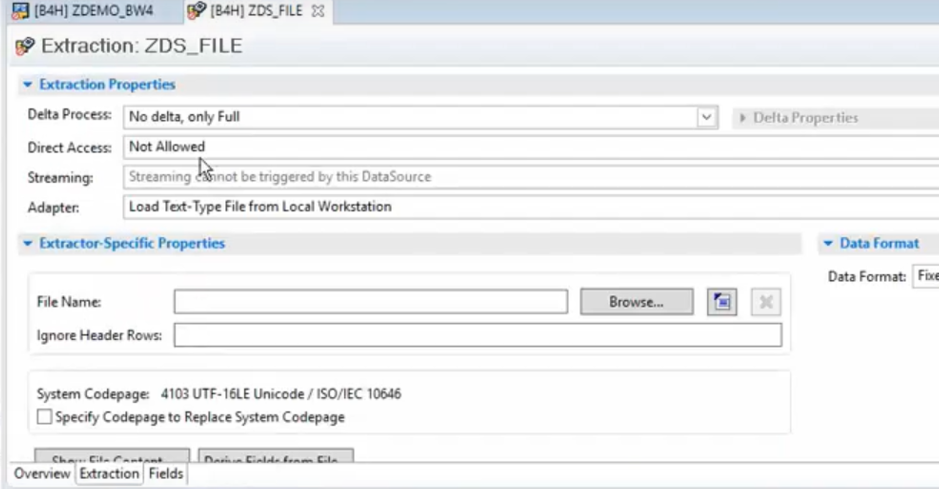
Next, specify a flat file name (which requires a separate program for further processing).
Alternatively, you can load text-type files from a local workstation (which also requires a separate program for further processing), but this option does not present any challenge in processing special characters.
InfoPackage Configuration
In order to configure the InfoPackage, follow these steps:
Character Set Settings
- Default settings: Unicode systems will use UTF-16LE encoding (code page = 4103).
- Direct input: allows you to override the system code page using the “character set” option:
- System code page: Default, set by system as 4103 (UTF-16LE Unicode).
- Frequently used SAP code page: 1100 (based on ISO 8859-1); covers the characters of Western Europe, North and South America, Australia, and Africa.
- Other SAP code pages: 1401 (Eastern European languages), 8000 (Japanese), 8400 (simplified Chinese), 8300 (traditional Chinese), 1500 (Russian), and more are also based on one ISO 8859 code page.
Replacement Character
When incoming flat files have a character that cannot be interpreted using algorithms of the configured code page, the system assigns a replacement character and the default is “#”.
Endian Setting
In a binary number consisting of multiple bytes (e.g. a 32-bit unsigned integer value), you can choose one of two options. The first is little endian, when the least-significant byte is encoded first and the remaining bytes are encoded in increasing order of significance. The second is big endian, when the most-significant byte is encoded first and the remaining bytes encoded in decreasing order of significance.
For binary and text mode files, the endian setting is “default,” and for legacy mode files, either little endian or big-endian settings could be configured.
Flat File Processing in Infopackage Routine or ABAP Program
In order to perform operations such as functional validations, etc., on the application server, the flat file needs to be processed using the below syntax:
OPEN DATASET <P_FILENAME> FOR INPUT IN <MODE> ENCODING DEFAULT IGNORING CONVERSION ERRORS.
*Perform File Operations such as reading, writing etc.
CLOSE DATASET <P_FILENAME>.
Where:
- < P_FILENAME> is the name of the application server file
- <MODE> is one of the most common modes, BINARY or TEXT
- TEXT MODE: The file is opened to be read or written line-by-line. Final space characters are deleted in this mode.
- BINARY MODE: The file is opened to be read or written to, without any line breaks. The exact content of memory is copied.
Each mode variant can be qualified by IGNORING CONVERSION ERRORS to allow the system to suppress any conversion errors at runtime while reading/writing from/to the flat file. Whenever a character is replaced by a replacement character while reading or writing, the exception defined in the class CX_SY_CONVERSION_CODEPAGE is raised and the specification IGNORING CONVERSION ERRORS allows it to suppress.
Replacing Special Characters in Transformations
The solution described above addresses the challenge of processing special characters through InfoPackages to the PSA layer. These special characters can be processed into subsequent layers, but might cause display issues in other upstream layers (e.g. Bex or SAP Business Planning and Consolidation or SAP Power BI). The next (but optional) challenge is to replace them with business-defined characters.
This post explores a simpler way of replacing special characters. Follow these steps.
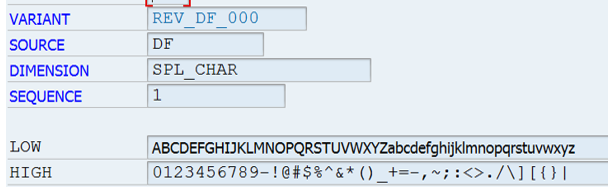
- Store all valid characters (alphabets, numbers, and commonly used symbols) in a custom table (like the one shown below). This is one way of storing special characters; there could be numerous other ways.
- Run the start routine within SAP BW transformation
- Access all valid characters (using keys such as VARIANT, SOURCE, DIMENSION, etc. in this example) and store them in a local variable. The character sets may need to concatenate depending upon how they were stored in the table.
- Compare the contents of the target description (or other fields) against this local variable. The logic could deploy “CO” (Contains Only) ABAP operations or any other character or string operation.
- Replace the contents of the target description with another pre-defined content.
Results
Using the workaround explored above, let’s see how this affects the data load. We configured an InfoPackage in our example with these criteria:
- Character set settings: direct input
- System code page: 4103 (overridden by character set)
- Character set (1100)
- Replacement character: #
- Endian setting: default
From there, we processed a flat file containing special characters (as shown in the first figure we looked at) through the InfoPackage. After successful processing, the data appears in the PSA layer with special characters shown highlighted.
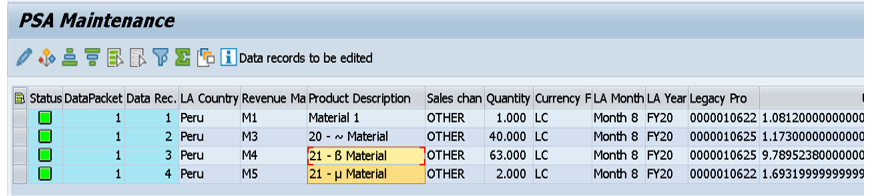
This data was further successfully loaded into the next layer (i.e. advanced DSO) with special characters shown highlighted.
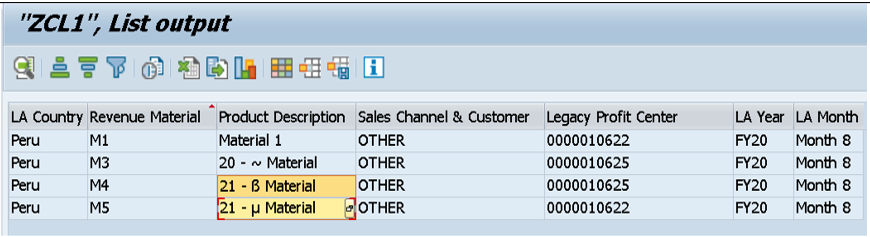
Conclusion
Organizations employing SAP Business Warehousing or SAP BW/4HANA utilize flat files for uploading a variety of transactional business data into their systems. These transactional data sets may contain special characters which are rejected when processed through standard data load processes, or even fail to process altogether. In this post, we presented a solution to help overcome this issue.
Thank you to Rajesh Hemnani for his assistance with this post.
This post was originally published 7/2021.



Comments