
Improved processing power, better algorithms, and the availability of big data are facilitating the implementation of machine learning for infusing intelligence into back-office processes and providing an intelligent ERP solution.
SAP S/4HANA’s underlying in-memory database, SAP HANA, increases speed, combines analytical and transactional data, and brings innovation with embedded machine learning capabilities. Thus, machine learning is natively integrated into SAP S/4HANA and can be used across an entire organization to optimize business operations, improve employee job satisfaction, and create better customer services.
With conversational UX, natural language interaction is enabled for SAP S/4HANA. However, when incorporating machine learning capabilities into SAP S/4HANA, various substantial challenges have been solved, like the following:
- How to integrate machine learning systematically into the business processes for ease of consumption: Machine learning models have been created by data scientists for decades. However, those models often resided in special tools, were consumed by experts only, and therefore added limited value.
- How to make machine learning enterprise ready: In the context of SAP S/4HANA, fused machine learning functionality must be enterprise ready, which comprises qualities such as compliance, lifecycle management, data and process integration, workload management, and performance.
The solution architecture explained in this post provides answers for the described challenges. But first, we introduce some basic terminology related to machine learning.
In machine learning, a desired function is realized by training a mathematical model with sample data so that the model learns to produce the desired outputs. The trained model is then used to compute outputs—for example, predictions or classifications—from actual input data. This is called inference.
Machine Learning Architecture
The architecture for machine learning in SAP S/4HANA has two flavors (see the figure below):
- Embedded machine learning, in which the machine learning application runs in the SAP S/4HANA backend
- Side-by-side machine learning using SAP Business Technology Platform (SAP BTP)
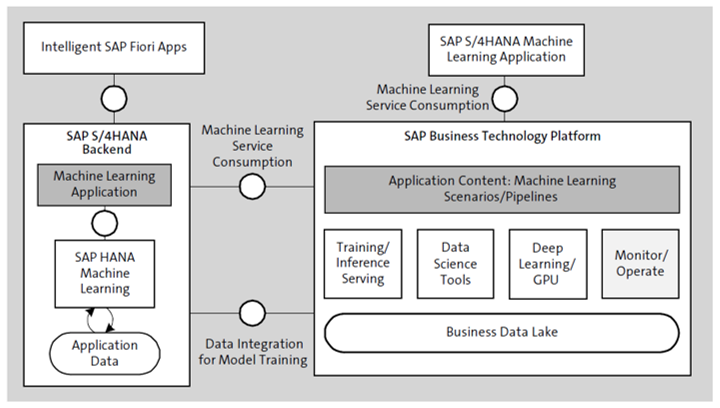
Embedded machine learning fits for use cases such as forecasting, categorization, and trending that can be solved with traditional algorithms, including regression, clustering, and time-series analysis. Usually, those algorithms aren’t allocating much memory and CPU time. Thus, they can be implemented within the SAP S/4HANA backend, close to the application data for training the models and to the business processes that consume the results. The embedded machine learning architecture is based on the machine learning capabilities of SAP HANA, which provides the necessary algorithms as part of the SAP HANA Predictive Analysis Library (PAL) and SAP HANA Automated Predictive Library (APL).
Use cases such as image recognition, sentiment analysis, and natural language processing require deep learning algorithms based on neural networks. For model training, these algorithms usually demand a huge volume of data and graphics processing unit (GPU) time. Such scenarios are implemented side by side with SAP S/4HANA on SAP BTP for several reasons:
- SAP BTP provides a scalable infrastructure for machine learning training and inference based on GPU technology. It provides state-of-the-art libraries such as TensorFlow and scikit-learn.
- The performance of SAP S/4HANA isn’t affected by training and inference jobs so that the transactional business processes don’t suffer.
- Many of the relevant scenarios work with data such as images, audios, text documents, historical logs, and external data. Such data typically isn’t stored in SAP S/4HANA but in the business data lake provided by SAP BTP.
Machine learning requires additional visualization capabilities on the UI, for example, for illustrating confidence intervals or forecasting charts. Thus, to embed machine learning capabilities in the UIs, corresponding intelligent SAP Fiori elements are used.
Embedded Machine Learning
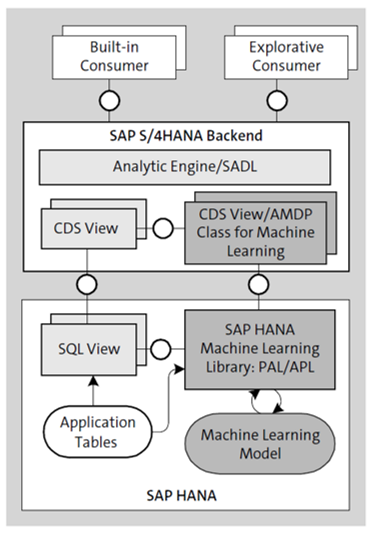
The embedded machine learning architecture is based on CDS views and uses the machine learning capabilities provided by SAP HANA (see the next figure). The algorithms for embedded machine learning can be performance-intensive because they typically must process high volumes of application data. Thus, for performance optimization, the algorithms must be processed close to the application data. SAP HANA contains the PAL and APL, which offer statistical and data mining algorithms. The functions provided by these libraries can be called from SAP HANA database procedures that are written in SQLScript. The algorithms require application data as an input for model training. This data can be read from application tables or from the SQL views that are created for the CDS views of the VDM on the database level. The trained models are exposed to business processes by wrapping them with CDS views for machine learning. These CDS views are based on ABAP classes, which contain ABAP-Managed Database Procedures (AMDPs) that call the trained machine learning model in SAP HANA. The CDS views for machine learning can be combined with other VDM CDS views and can then be exposed to the consumers. By consuming machine learning models through CDS views, existing content (e.g., VDM views) and concepts such as authorization, extensibility, or UI integration, are reused. This results in a simple and very powerful solution architecture. The inference outcomes are integrated into business processes and provided to the right person, in the right place, and at the right time. The embedded machine learning architecture is based on CDS views and uses the machine learning capabilities provided by SAP HANA. For the majority of SAP customers, this already makes SAP S/4HANA an intelligent solution without the need of side-by-side machine learning, especially when the prediction algorithm can be automatically found by the embedded PAL/APL engine.
Side-by-Side Machine Learning Architecture
SAP BTP provides a data lake for business data. Thus, application data can be extracted from SAP S/4HANA for the training of machine learning models. As illustrated in the figure below, preprocessing and postprocessing of the application data are based on pipelines. The pipeline engine orchestrates complex data flow pipelines and is based on scalable infrastructure provided by SAP BTP, Kubernetes environment. Based on the application data available, data scientists perform exploration and feature engineering to define machine learning models. For this, common data science tools such as Jupyter Notebook and Python (see https://jupyter.org) are supported. For deep learning scenarios, SAP BTP provides a GPU infrastructure.
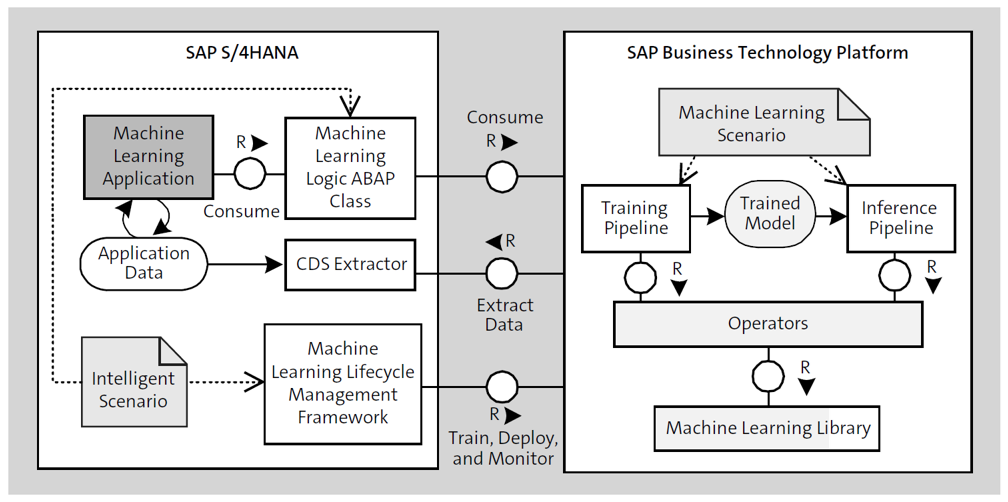
To implement machine learning use cases, applications must define machine learning scenarios and model pipelines. SAP BTP organizes each machine learning use case by the artifact machine learning scenario. This contains all development entities that are required for the implementation of a specific machine learning use case. Inference and training processes are developed as pipelines comprising sequential and parallel tasks. In particular, for each machine learning scenario, a training pipeline is provided that receives the training data from SAP S/4HANA and processes it to train the algorithms for the specific use case. Structured data is handled by the pipeline operator for CDS views. This pipeline operator extracts application data from SAP S/4HANA based on CDS views for training algorithms. The training and inference pipelines are exposed by REST services. SAP S/4HANA applications invoke those remotely and integrate them into the business processes and UIs. Thus, machine learning capabilities are provided as built-in functionality. On the SAP S/4HANA side, the intelligent scenario is the corresponding artifact to the machine learning scenario of SAP BTP. The intelligent scenario is a design-time artifact that represents a machine learning use case and contains metadata such as the name and description of the use case. In particular, it encompasses the ABAP class that is implementing the consumption API of the machine learning model.
The machine learning lifecycle management framework ensures uniform integration and operation of side-by-side machine learning scenarios. For this, the framework provides generic functionality for training, deployment, and monitoring of side-by-side machine learning models. It enables harmonized integration of machine learning capabilities into SAP S/4HANA business processes by supplying standardized interfaces that the ABAP machine learning logic class must implement.
Machine Learning in SAP S/4HANA Applications
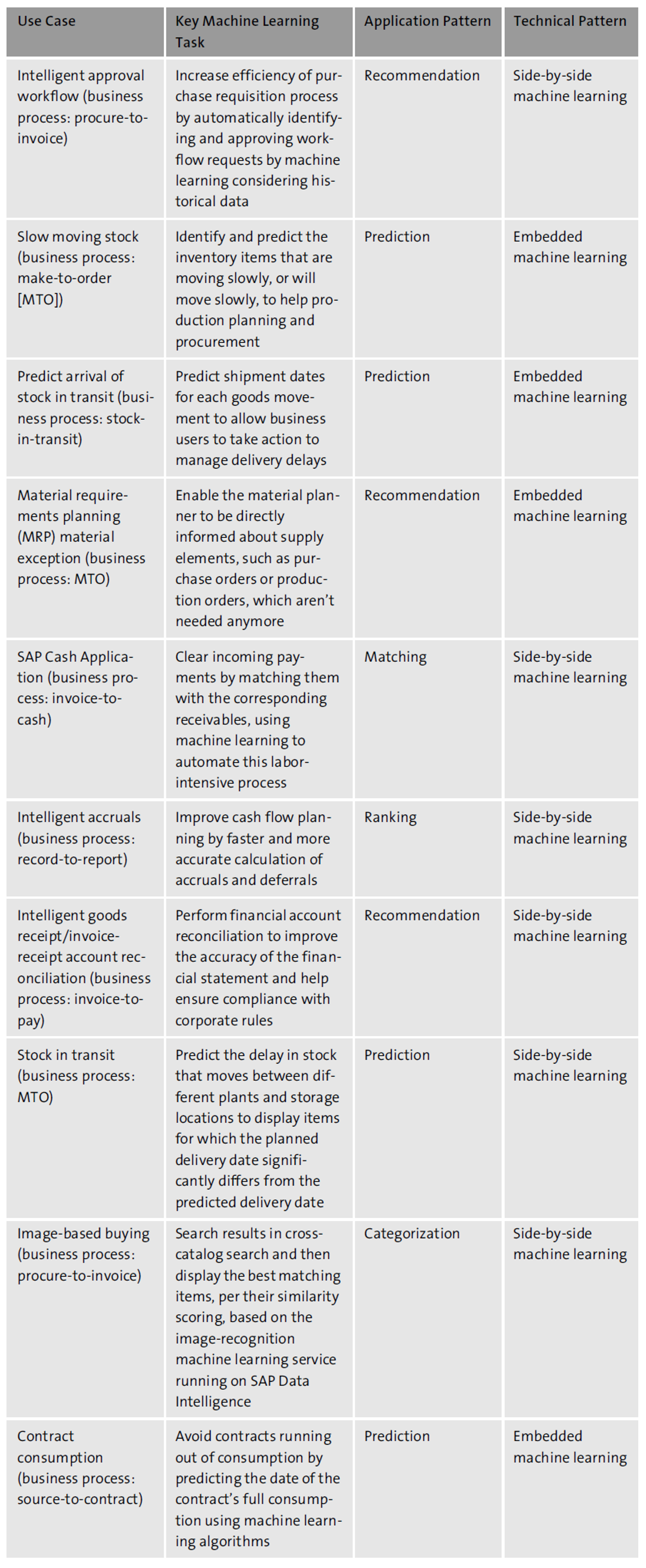
Numerous machine learning use cases have been delivered for SAP S/4HANA. Those use cases follow technical patterns such as embedded and side-by-side machine learning, as well as the following machine learning application patterns.
Matching
Assigns relationships and detect similarities and anomalies in a given data set. Manual matching is very time-consuming for users, but intelligent systems can significantly speed up matching decisions by using machine learning methods. The system can present one or more strategies and their qualities to link similar objects. Users then only need to approve, reject, or adjust the suggestions to their needs. For developing matching patterns, commonly used algorithms include XGBoost, multilayer perceptron, k-means, k-nearest neighbors, and neural networks.
Recommendation
Proposes data sets or actions based on the current context. Intelligent systems can help users by recommending appropriate content or suggesting an action or input the user may prefer. Content, input, and solution recommendations are the common types. Typical machine learning algorithms used in this context are social analysis, XGBoost, multilayer perceptron, text analysis, and recurrent neural networks.
Ranking
Distinguishes between relevant and less relevant data sets of the same type in relation to the current context. Items in a group are ranked by comparing criteria that are relevant for the user’s business context, such as amount, priority, or score. We differentiate between a ranking that uses an available value and a ranking based on a calculated machine learning score. Typical machine learning algorithms used in this context are XGBoost, k-means, Gaussian mixture model, k-nearest neighbors, and neural networks.
Prediction
Predicts future data and trends based on patterns identified in past data, taking into account all potentially relevant information. Intelligent systems based on predictive models significantly reduce the cost required for companies to forecast business outcomes, environmental factors, competitive intelligence, and market conditions. Parametric and nonparametric classes of predictive models are differentiated. Typical machine learning algorithms used in this context are regression, random forests, decision trees, and neural networks.
Categorization
Assigns data sets to predefined groups (classes). It also discovers new groups (clusters) in the data sets, such as grouping customers into segments for appropriate product offerings, targeted marketing, or fraud detection. Categorization is a complex task, of which intelligent systems can help increase the automation level by applying machine learning algorithms such as classification, clustering, XGBoost, kmeans, and neural networks.
Conversational UX
Interacts with the system based on natural language conversation. Being able to have a conversation with a digital assistant for business processes is a key part of the UX for an intelligent application. The strategic direction at SAP is to provide a uniform concept and framework for each pattern for implementation. Thus, the machine learning application patterns can be applied as reusable building blocks by development teams to accelerate the implementation of machine learning use cases. To explain all machine learning applications delivered by SAP S/4HANA would go beyond the scope of this post, but we list the top 10 machine learning applications in this table
Editor’s note: This post has been adapted from a section of the book SAP S/4HANA Architecture by Thomas Saueressig, Tobias Stein, Jochen Boeder, and Wolfram Kleis.



Comments