
Every organization, irrespective of its size, location, business line, or industry sector, has to deal with the challenges of duplicate records in its IT landscape.
These duplicates might be in the system knowingly or unknowingly. With focus on and awareness about the importance of good data quality, companies have done a lot of work in this area in recent years, and with the help of technology innovations, they are in a better position to deal with duplicates in their IT landscape.
Reasons for Duplicate Data
There are many reasons that duplicate records end up in any company’s landscape.
Merger and Acquisitions
A merger or acquisition between companies can often be the reason behind most of the duplicate master data in the landscape. The new systems in the landscape potentially have similar master data records (e.g., vendors, customers, or business partner entities with whom both companies have been doing business). Normally, consolidation or data quality projects during or after the merger help to overcome such duplicates. However, due to various business and strategic reasons, companies do defer the projects needed for consolidating master data.
Search Methods and Technology
An inaccurate, slow, or difficult-to-use search may also contribute to the reasons a business user may not be able to complete the due diligence before submitting a new request and, hence, end up creating a duplicate in the system.
Manual Errors
Human error, lack of proper training, and ignorance or lack of awareness on the part of the business users working with master data are also common contributors to duplicate master data.
Deliberate Due to Business Reasons
Some business partners use different addresses for their sister companies for performing some business functions (e.g., delivery, collection, etc.), so separate vendors and suppliers are created in the system based on different addresses.
Different Entities with Some Matching Attributes
In some cases, master data records have many matching attributes but are genuinely separate, independent entities with no relation that fall under the category of potential duplicates due to the defined matching strategies. A system’s matching strategies should be intelligent enough to ignore such cases in the list of potential duplicates.
How to Reduce Duplicate Data
While two or more records existing in the database while representing the same entity are considered duplicates, in daily life, it could be a complex job to differentiate between real duplicates and look-alike, unrelated records. It’s not practical and justified to rely completely on human decisions for 100% accuracy without any human error involved. In addition, for various reasons, it’s impossible to lay down a set of business rules and logic that a system can use to determine duplicates with accuracy in all possible scenarios.
Considering the challenges explained earlier, it makes sense to use a hybrid approach with multiple human interventions while leveraging the system search and duplicate check capabilities. The SAP Master Data Governance search and data quality process is very robust and minimizes the probability of duplicates entering the system to almost a negligible amount. Following are the multiple-step approaches used in central governance to handle duplicates more effectively and proactively.
Note: As a best practice before creating a new master data record, the requester should always perform a search in the database to determine whether the entity already exists in the database. Intuitive, accurate, and robust search capabilities in SAP Master Data Governance will help to ensure that the requester doesn’t overlook existing records and submit change requests for potential duplicates.
By using search and duplicate check capabilities, the system identifies and presents the list of potential duplicates with respective scores based on defined attributes and threshold limits. While submitting the change request in SAP Master Data Governance, a requester may again get an opportunity to make a decision if the change request carries a potential duplicate. The following figure shows the SAP Master Data Governance UI when a potential duplicate is presented.
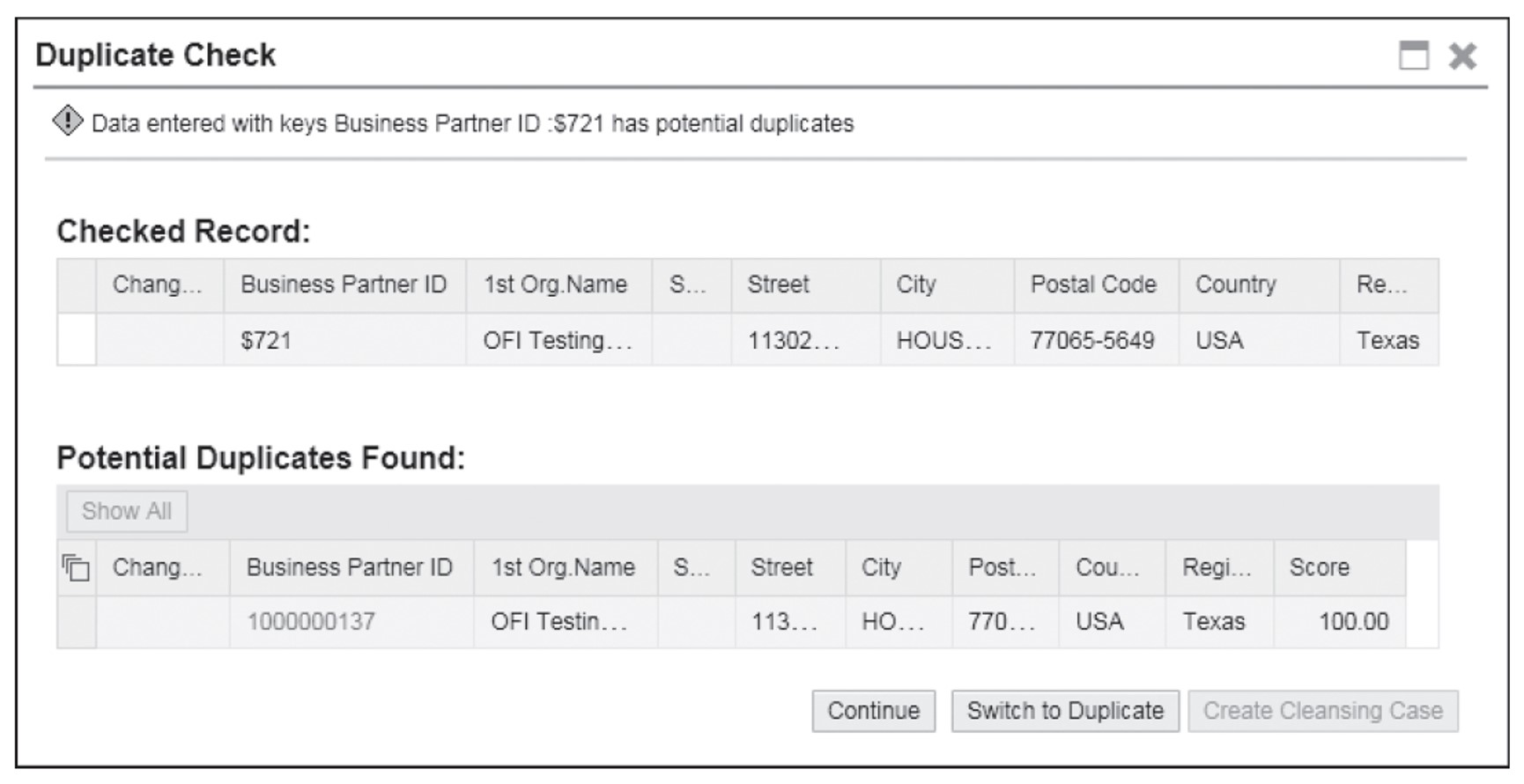
At this time, you have the option to trigger a cleansing case but only between the potential duplicates found and presented in the lower section of the Duplicate Check screen where a new governance path will help resolve the existing duplicates. For the new record being submitted, results of the cleansing case may end up merging the records, or the experts may reject the proposal of merging the duplicates if the lookalike records are later identified as different entities.
Note: Cleansing cases in SAP Master Data Governance are supported only for business partner data; no other data domains are supported for this functionality.
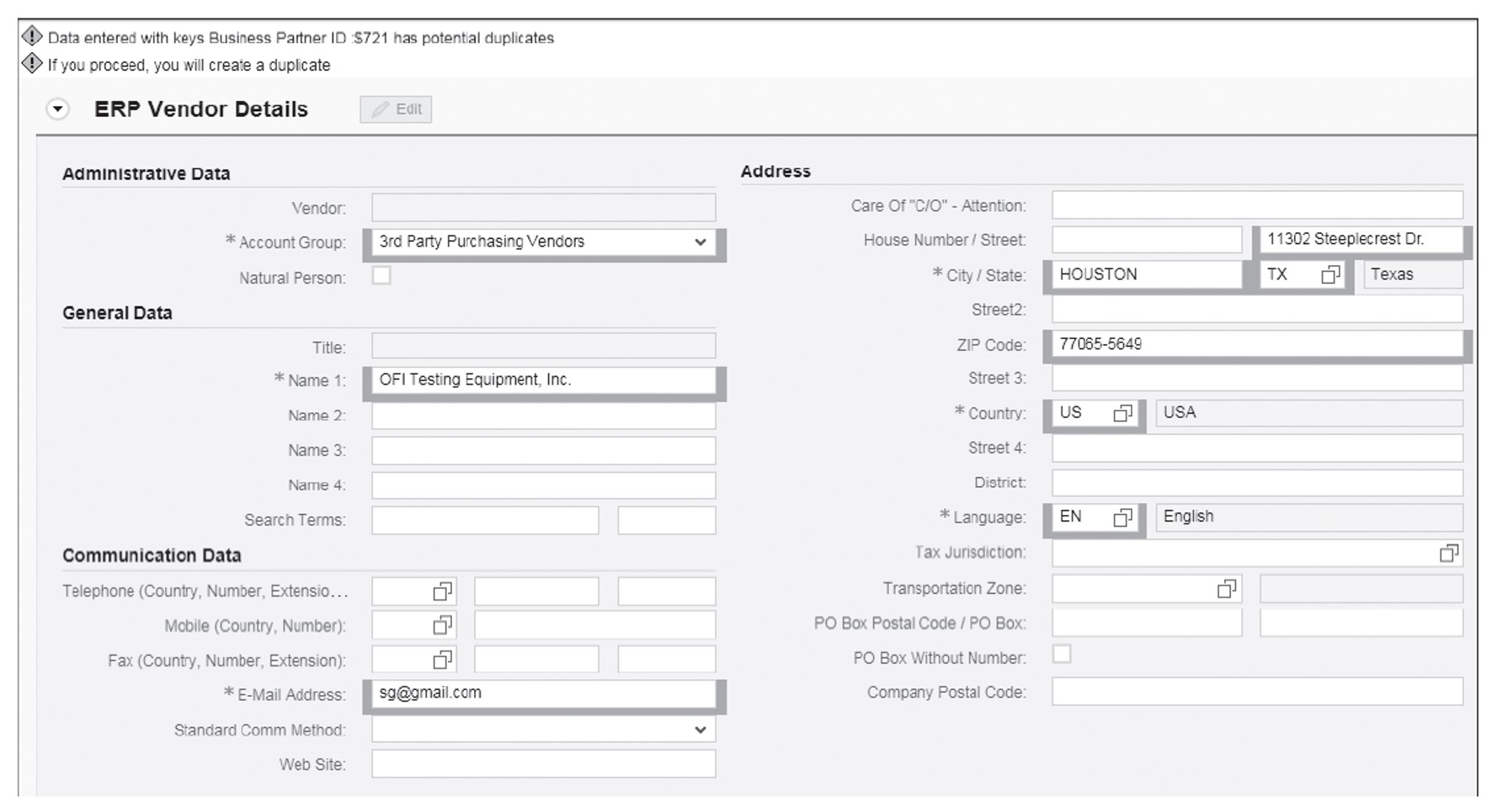
The next figure shows the screen you’ll see after deciding to continue and ignoring the potential duplicate presented by the system.
Additionally, after the SAP Master Data Governance change request is submitted in the subsequent approval steps, approvers may also receive a list of potential duplicates from the system and can decide to continue, send the change request back, or trigger a cleansing case.
Note that for duplicate check purposes, the SAP Master Data Governance system uses the same search providers as were used for performing the search. The next figure shows some common search options used during the duplicate check.
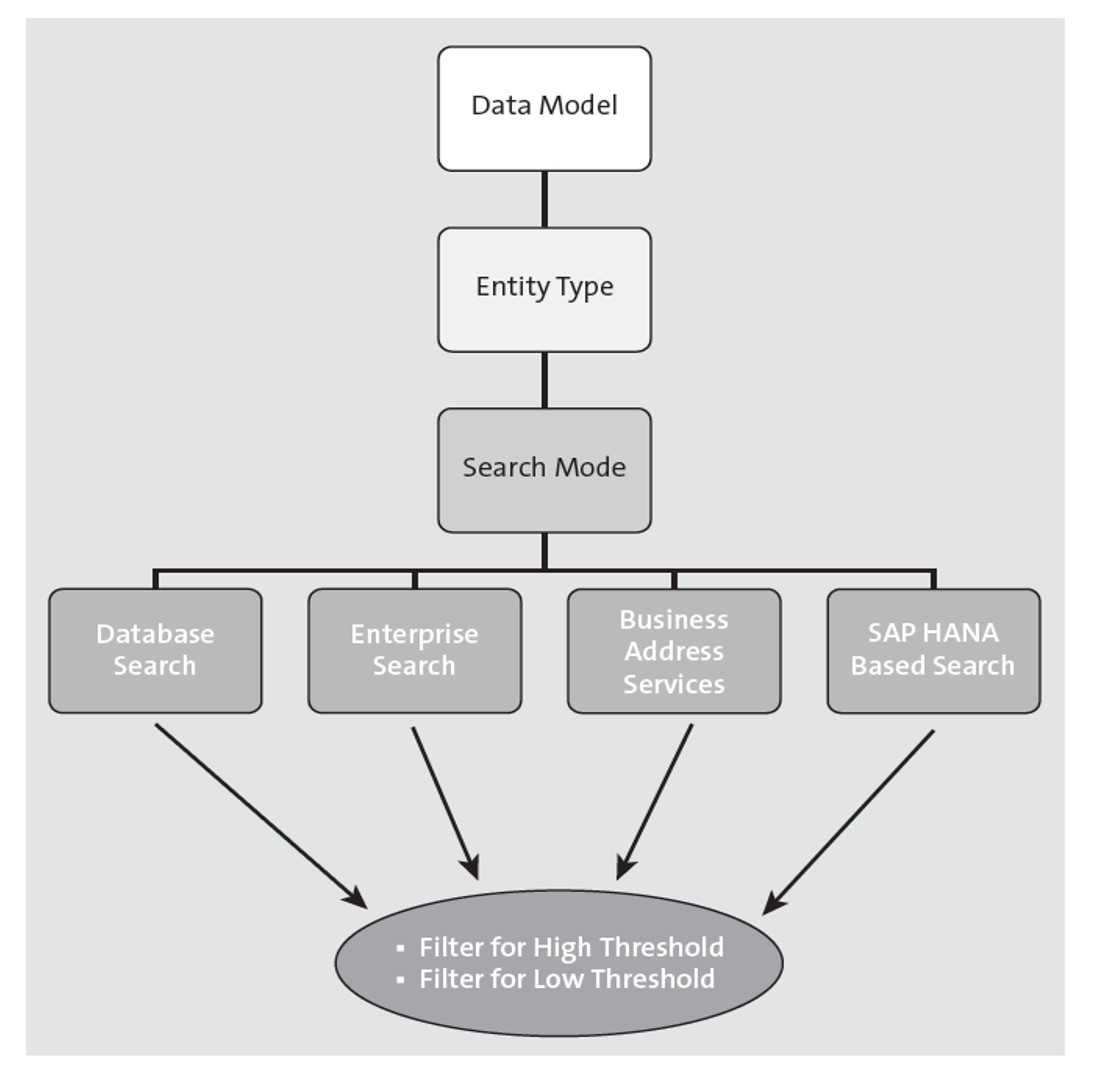
As shown in the figure below, in the Configure Duplicate Check for Entity Types Customizing activity based on the respective data models, a Search Mode is configured as well as the lower threshold (Low Thres) and upper threshold (High Thres) that should be applied. Low threshold signifies that records with a matching score less than the low threshold values won’t be considered as duplicates, whereas records that have a matching score greater than the low threshold value will be considered as potential duplicates.

Records with matching scores greater than or equal to the high thresholds are considered as identical and are still presented to you for subsequent follow-up actions. Low threshold values are relevant for SAP HANA search, whereas it’s not applicable for database search, remote key search, or SAP NetWeaver Enterprise Search/SAP HANA enterprise search.
There are additional match profile-related configurations in search applications as required for duplicate check functionality in SAP Master Data Governance.
The next figure displays a mandatory process modeling configuration required at each change request type step level. This is a prerequisite for triggering duplicate checks for a workflow step.
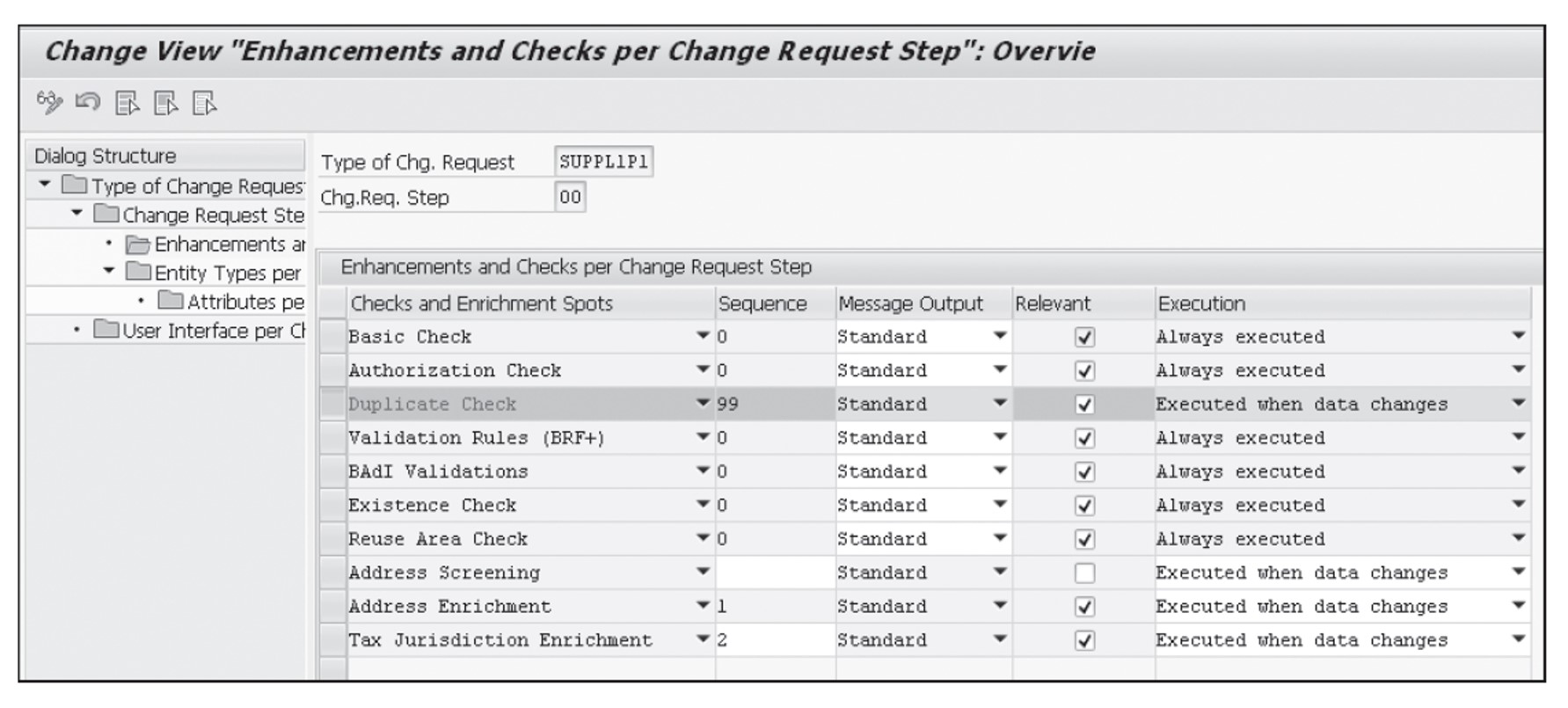
Note: As an SAP Master Data Governance user, if you want to see all column headings and content completely when the duplicate check is carried out, SAP Note 2667744 helps to change the layout of the popup by making the column headings and content readable and auto-resizing dynamically.
Conclusion
Reducing the amount of duplicated data both makes users’ lives easier, and keeps systems from being bloated with unnecessary information. This blog post discussed the reasons that duplicate master data may exist in a system, and how SAP Master Data Governance can help identify and remove such data.
Editor’s note: This post has been adapted from a section of the book SAP Master Data Governance: The Comprehensive Guide by Bikram Dogra, Antony Isacc, Homiar Kalwachwala, Dilip Radhakrishnan, Syama Srinivasan, Sandeep Chahal, Santhosh Cheekoti, Rajani Khambhampati, Vikas Lodha, and David Quirk.



Comments