
Traditional databases are based on designs that were developed decades ago. The technical conditions, as well as the usage requirements, during this time differed from today’s expectations.
Limitations of Traditional Databases
Traditional databases have been enhanced, but their ability to adapt to new challenges is limited due to compatibility reasons. From the perspective of business application software, traditional databases lead to critical limitations and can complicate or even hinder the simplification, acceleration, and integration of business processes. The following characteristics of traditional databases can be obstructive, for example, when redesigning your business processes:
OLTP vs. OLAP
Users of database solutions have to decide whether they want to analyze data (online analytical processing, or OLAP) or update data (online transaction processing, or OLTP). However, in many situations, a combination of both views makes sense, for example, for forecasts and simulations or for making decisions on the basis of real-time data.
Technical Restrictions
Traditional business applications have to deal with various restrictions, which complicate things for users. Examples include locks that occur so that only one user can work on a data set at a time, which slows down processes. Another factor is the delay resulting from internal data editing processes. Updates carried out by other users, or even by the same user, are sometimes written to the relevant system tables with considerable delay.
Integration
In traditional applications, raw data is usually first internally prepared and consolidated via aggregates. These aggregates obey the individual logic of each application. The use of the data by other applications is thus subject to a time delay on one hand, as already mentioned, and semantic knowledge about the respective application aggregate is required on the other. Consequently, the data first needs to be translated into the data model of the other application. For this purpose, interfaces must be available or must be developed. Integration on the basis of such an architecture thus has disadvantages based on costs (development and maintenance of the interfaces) and lacking real-time access.
SAP HANA: An In-Memory Database
The current database architectures use in-memory databases that enable new business processes across all lines of business. The following sections describe the characteristics of SAP HANA and describe why no other in-memory database is currently compatible with SAP S/4HANA.
SAP HANA
At the turn of the millennium, two basic changes arose in hardware development: (1) multicore processor architectures emerged and, with them, the option of substantial parallelization, and (2) memory evolved from being relatively expensive and limited into being widely available.
Due to the memory restrictions with regard to availability (i.e., price and addressability), the data in software architectures was mainly stored on the hard disk, and only some data was stored in the memory. Accessing in traditional databases was limited by hard disk processing speeds. In in-memory databases, the hard disk is only used to store, archive, and restore data. The data itself is permanently kept in the main memory.
In contrast to other in-memory databases, SAP HANA has further unique characteristics: SAP HANA is not only an ideal generic database but has also been optimized for business applications due to SAP’s holistic experiences with this kind of applications.
A key result of SAP’s experience is that the data in SAP HANA is stored in column-based tables, while the data in other databases is stored in row-based tables (see figure below). Why is this relevant? In business applications, most data is accessed “per column”: Usually, the values of a field or a selection of fields are selected and edited. Rarely is an entire set of rows required. If SELECT statements are executed using column indexes, much smaller volumes of data need to be processed. Moreover, the values in the columns can usually be easily compressed—in particular under the conditions given for business applications, which consist of similar data.
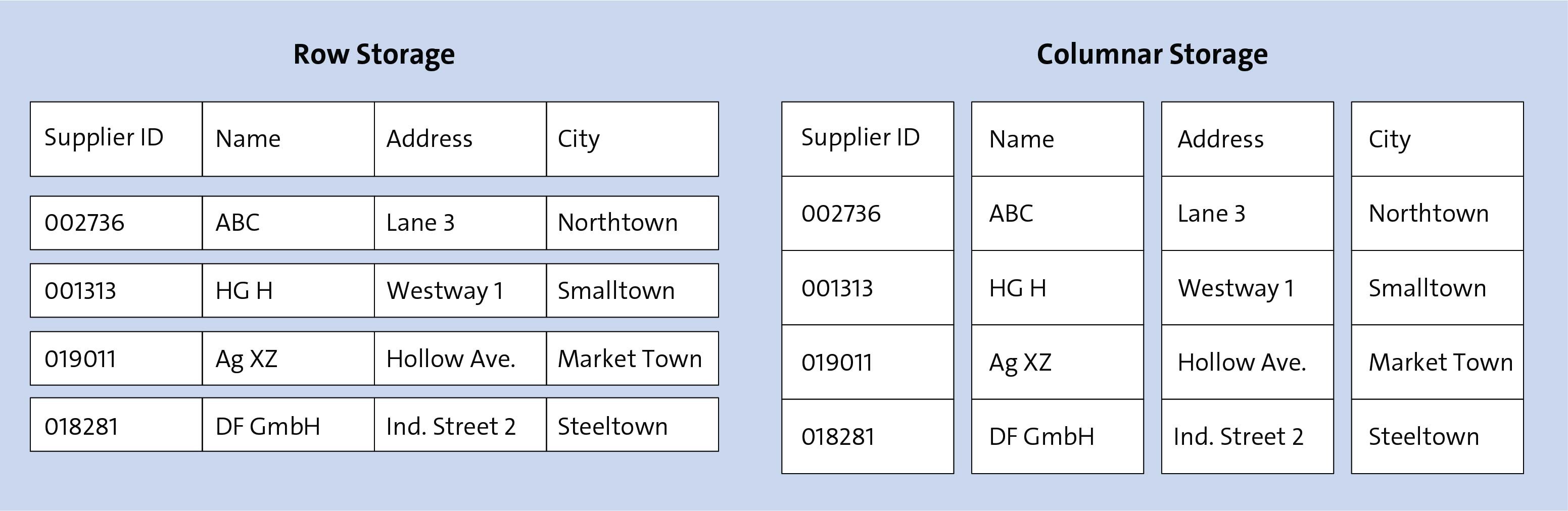
Another benefit of the SAP HANA database is that it has been optimized in such a way that the main business data operations can be executed with high performance. For this purpose, SAP HANA uses multicore CPUs for parallelization. In addition, algorithms are optimized using assumptions about the types of updates, inserts, and deletions that are carried out frequently and should consequently be the focus for high performance.
The Data Model
SAP S/4HANA is designed to fully exploit the benefits of SAP HANA described in the previous section. With this focus on SAP HANA, the following consequences arise for the data models in SAP S/4HANA:
- Omitted aggregates
- Redesign of existing ABAP Dictionary tables
- Code pushdown
The following sections discuss each of these consequences in greater detail.
Omission of Aggregates
To compensate for poor speed of traditional databases, data was previously consolidated in aggregate tables. The applications then accessed these aggregate tables to read the data. However, these aggregates had the following disadvantages: Due to the consolidation, entries in the aggregate tables always lagged behind entries in the original tables. This delay increases with the growth of the volume of data that needs to be processed.
Another disadvantage is that the aggregation uses assumptions of the content as a prerequisite for consolidation. As a result, processing this data from a different perspective is usually not possible without reworking the aggregation and thus can be a rather complicated task. For this purpose, you’ll have to use the original data, which reduces processing speed.
The figure below shows an example of a target architecture with a simplified data model for sales documents after migrating from SAP ERP to SAP S/4HANA.
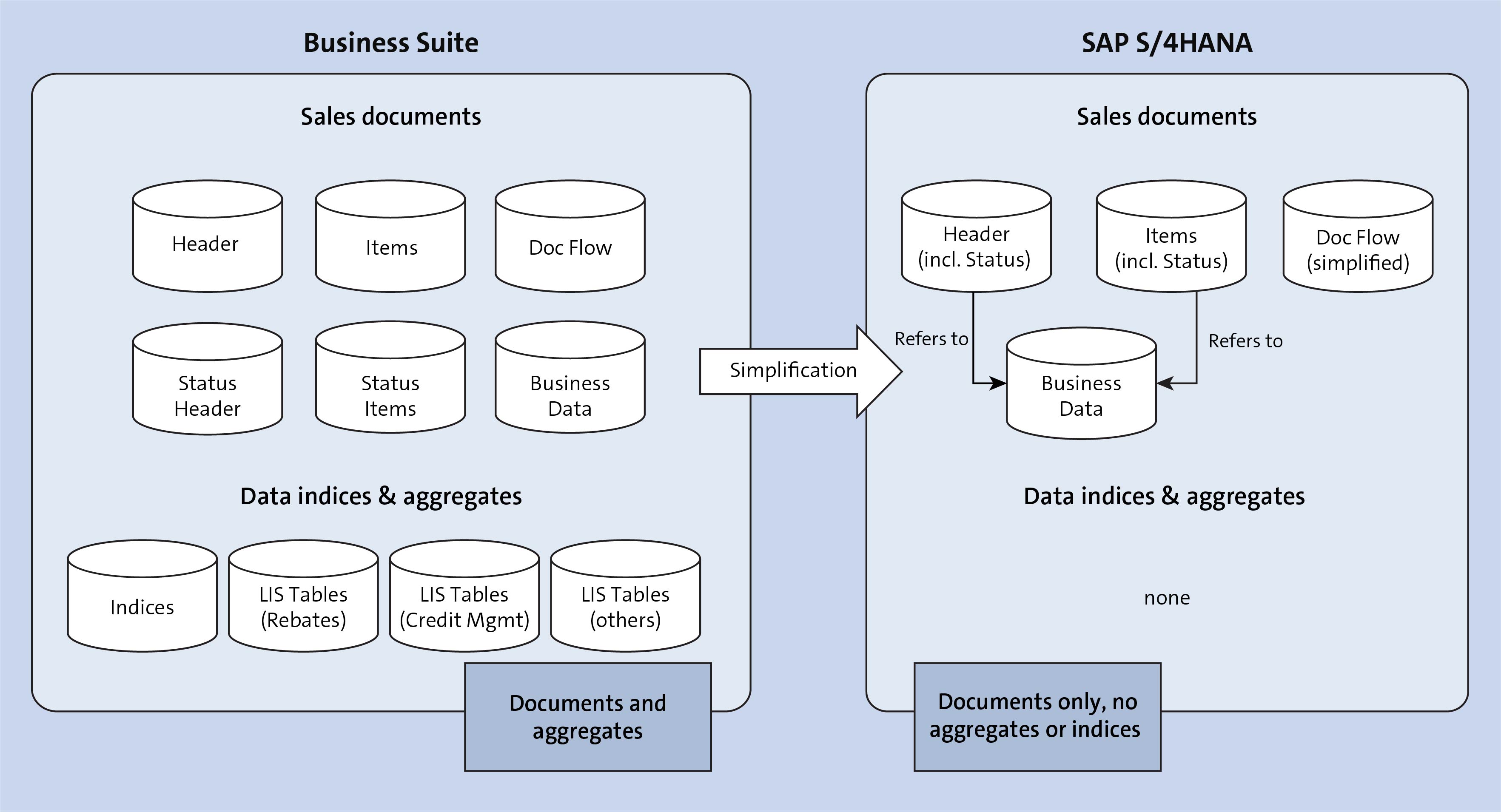
The usual aggregate tables were omitted in this case. All new SAP HANA-optimized applications directly access the original data.
Note that the aggregates continue to exist in the new data model: The database can emulate the tables in real time. For this purpose, SAP S/4HANA provides predefined database views. These views simulate the aggregates in real time so that existing applications that have not been optimized for SAP HANA can be deployed smoothly.
As a result, you’ll still have read access to existing custom developments, such as reports, and you can usually still use these reports without needing adaptations to the new data model.
Redesign of Existing ABAP Dictionary Tables
In addition to omitting aggregates, the example shown above also illustrates that the architecture for the storage of original data is also partly optimized. In this context, you must keep in mind that the data models in SAP ERP had been developed over several decades. On the one hand, these data models had to be compatible with all databases; on the other hand, rigid changes would have led to problems with SAP ERP EHP upgrades, which were promised and expected to be easy to use.
With the focus on the SAP HANA database and the clear differentiation to existing products, SAP S/4HANA now also allows for redesigning the data architecture in general. In this process, data storage is further optimized for SAP HANA, for example, to enhance the compression rate or optimize the general performance.
Code Pushdown
Another innovation in SAP S/4HANA is that procedures can be directly transferred to the database. In the traditional SAP Business Suite, the ABAP kernel decoupled the application from the database to ensure compatibility to any type of database. Consequently, the raw data first had to be loaded from the database and then concatenated in the application to carry out complex, data-intensive selections and calculations.
In SAP S/4HANA, some data-related processes are pushed down to the database itself, which accelerates the entire process, which is known as code pushdown. Code pushdown can be executed either in ABAP using Open SQL or via SAP HANA content created in SAP HANA Studio.
How does this affect existing custom code enhancements? Because existing Open SQL data access still works, you can continue to use existing enhancements and only have to adapt them in exceptional cases. However, these codes do not exploit the full potential of SAP S/4HANA. Thus, when you plan to migrate to SAP S/4HANA, you should check which custom codes should be rewritten and optimized. Because you can address custom code at any time after migrating SAP S/4HANA, you’ll enjoy greater flexibility in planning.
Note that existing sidecar scenarios must be revised with high probability due to the changes in the data models. In these scenarios, data of (several) separate systems is replicated into one central system. This replication usually writes directly to the database tables. Because the latter have changed in SAP S/4HANA, the replication rules must be adapted accordingly and new mappings must be made.
The New Finance Data Model in SAP S/4HANA
SAP is a highly integrated system that manages data from various areas of the business, such as accounting, sales, purchasing, production, and so on.
This integration comes with a certain degree of complexity, which results in the data being stored in many different tables. Thus, sometimes, even for experienced consultants, finding the best way to find and retrieve the relevant data can be a challenge.
In the area of finance, traditionally, financial accounting and controlling (management accounting) were separate applications in SAP, which was a design mainly driven from traditions in the German-language world. However, in today’s globalized world, a strong case exists for the integration of processes and applications and the simplification of systems. SAP’s answer to this need is the excellent SAP S/4HANA Finance solution, which provides full integration of the financial accounting and controlling applications, both from a process point of view and a database point of view.
We’ll discuss in detail the two key elements of the new finance data model in SAP S/4HANA: the Universal Journal and real-time integration between financial accounting and controlling.
Universal Journal
The Universal Journal provides a solution for a seemingly simple but, until SAP S/4HANA, elusive goal: bringing together and fully integrating all financial information in one single line-item table that has all financial accounting, controlling, and material valuation information. Previously, for many reasons, multiple financial accounting and controlling tables stored data that now, with SAP S/4HANA, is stored in the Universal Journal. Some tables were based on business processes on the presumption that financial accounting and controlling should be separate applications, which isn’t the case in the current business world. Some reasons were technical: only the amazing speed and columnar design of SAP S/4HANA makes it technically feasible to have such a vast amount of data in a single table.
The Universal Journal is a new table in SAP S/4HANA, called table ACDOCA. This line-item table brings together information from the general ledger, controlling (management accounting), asset accounting, and material ledger, as shown in this figure.

As shown, table ACDOCA, the Universal Journal table, combines fields that previously were stored in the tables of various financial accounting and controlling functionalities. Once a financial document is posted in table ACDOCA, fields such as cost center, asset number, profitability segment fields, and so on are also recorded. Thus, a whole lot of tables from controlling, fixed assets, and the material ledger have been made redundant because the information is now integrated in the Universal Journal.
For compatibility reasons, these tables still exist as core data services (CDS) views so that they can still be referenced in custom programs, which is important for companies pursuing brownfield implementations of SAP S/4HANA.
The table below shows the main financial accounting tables that are now obsolete in SAP S/4HANA because their data is part of table ACDOCA.

Tables BSIS, BSAS, BSID, BSAD, BSIK, and BSAK are index tables containing open and cleared items for general ledger accounts, customers, and vendors, which are now all in table ACDOCA. Tables GLT0 and FAGLFLEXT are totals tables (table FAGLFLEXT was introduced with the new general ledger), which are now also obsolete because SAP S/4HANA calculates totals on the fly. The next table shows other important controlling, fixed assets, and material ledger tables that are now obsolete due to the Universal Journal.

As you can see, now in SAP S/4HANA, the Universal Journal combines the key tables of all the financial applications into a single table, which is commonly referred to as the single source of truth. Now, you have all the information you need to present the financials of your company in one place, which is an enormous advantage compared to previous SAP releases and to other enterprise resource planning (ERP) systems.
Real-Time Integration with Controlling
The real-time integration of financial accounting with controlling follows logically from the integration design of the Universal Journal as discussed earlier. Indeed, because controlling-relevant data now is brought together with financial accounting data in the Universal Journal, no technical obstacles prevent the system from providing real-time integration between any financial accounting and controlling documents.
In the past, the reconciliation ledger had to be configured to ensure that financial accounting and controlling were always in sync. This configuration is no longer required because, with the real-time integration with financial accounting, such reconciliation is obsolete. In addition, secondary cost elements are created as general ledger accounts to ensure this integration.
In SAP S/4HANA, controlling documents are still generated along with financial accounting document numbers. However, even internal controlling movements, such as the reallocation of costs from one controlling object to another, also generate financial accounting document numbers, thus ensuring real-time integration, which wasn’t the case in SAP ERP. In terms of configuration, document types that are used for posting in controlling are defined to post to general ledger accounts as well. These document types are linked to the controlling internal business transactions and generate financial accounting postings as well as controlling postings.
The Virtual Data Model in SAP S/4HANA
The virtual data model (VDM) forms the basis for all specific data models of application data in an SAP S/4HANA system: analytical models, transactional models, and API models, in particular OData services and data interfaces.
For naming, all these models use the names assigned in the VDM to ensure uniformity. Names in VDM focus on business semantics and understandability. They are based on English terms that are combined according to an UpperCamelCase schema.
SAP object types form the business nucleus of VDM. Their names follow strict rules and an approval process. The names of SAP object node types use the object type name (or an abbreviation) as a prefix.
Names must not be too generic, otherwise collisions with similar but still different objects occur. Therefore, names are often prefixed with qualifiers to distinguish, for example, a SalesOrder from a PurchaseOrder. VDM deliberately doesn’t use a separation by name spaces but defines unique names for business concepts.
For country-specific or industry-specific objects and some SAP products, however, standardized prefixes are applied. For country-specific objects, the country ISO code is used, for example, TW_TaxCode, and for industries or products, a three-character abbreviation is used such as OIL for the oil and gas industry, or ACM for SAP Agricultural Contract Management.
Field names in CDS are limited to a length of 30 characters. This enforces the use of abbreviations for proper naming of complex matters. The abbreviations are standardized; that is, every abbreviation has exactly one expanded term. The abbreviation Qty, for example, always means Quantity. This allows you to always expand the full name from an abbreviated one.
The base name of an entity is usually derived from the related SAP object node type and describes an instance of that entity.
Field Names
Field names are defined in the same way as the names of object node types. There are, however, many more data fields with individual semantics, each of which gets a unique field name. Uniqueness allows the recognition of relations between different CDS entities from the field names. This option is particularly helpful in analytical scenarios when data from different sources are combined. The uniqueness is technically supported by enforcing different field names for fields with different data types in the ABAP Data Dictionary.
Fields not only identify instances of an entity or of an SAP object node type but also denote quantities, amounts, times or dates, texts, and so on. These different categories are distinguished by the representation term of a field name. The naming approach for different representation terms is presented in the following list.
Identifier Field
An identifier field is used for the unique identification of an instance of a certain entity or of the corresponding SAP object node type. A sales order number, for example, identifies a particular sales order. In this case, you choose the denomination for an instance of the entity, for example, SalesOrder. You can optionally use suffix ID in the name to emphasize the representation term; however, the suffix is omitted usually.
Universally Unique Identifier (UUID)
If a universally unique identifier (UUID) exists beside the common ID, you should use a field name with suffix UUID, for example, BusinessPartner-UUID. Other alternative identifiers can get a suffix as well, for example, WBSElementInternalID or PersonExternalID. Sometimes, the same entity is referenced by multiple fields of a view, perhaps in different roles. If so, additional qualifiers are used, for example, SenderCostCenter and ReceiverCostCenter.
Code
A code is a value in a fixed value list that is only changed by altering the system configuration, for example, a code for languages (Language) or currencies (Currency). For these field names, suffix Code can be omitted as well. Semantic subtleties are expressed by qualifiers, for example, CompanyCurrency or CountryISOCode.
Indicators
Indicators represent Boolean values. An indicator’s name is a statement that corresponds to the logical value of the field, for example, OrderIs-Released or NotificationHasLongText.
Amount and Quantity Field
The name of an amount field can contain a reference to its currency, for example, NetAmountInDisplayCurrency. As the relation to the currency is also expressed by annotations, this information can be omitted, for example, TaxAmount. Quantity fields are similar, for example, OrderQuantity or MinDeliveryQtyInBaseUnit.
Counters and Durations
For counters that specify the number of things, prefix NumberOf is used, for example, NumberOfRecipients. Durations can have a related unit field, for example, ForecastedDuration and ForecastedDurationUnit, but it’s not mandatory. In such cases, the unit should be included in the field name, for example, TripDurationInDays.
Points in Time
For points in time, DateTime is part of the field name, for example, CreationDateTime. For dates, Date is appended, and for times, Time is appended.
Rates and Ratios
In field names for rates or ratios, Percentage and Fraction are forbidden. The following combinations can be used instead: ConditionRateInPercent, UtilizationPercent, ExchangeRate, and ProbabilityRatio.
The name of a parameter of a VDM view consists of prefix P_ and a semantical name, which is formed like a field name and often actually used as a field name, for example, parameter P_DisplayCurrency.
An association of a VDM view points to another VDM view. Usually, the first letter of the target view is omitted, and the remainder is used as the association name. Association _Customer, for example, often points to view I_Customer. Alternatively, you can abbreviate the association name if it remains understandable in its context. The association from view I_SalesOrder to I_SalesOrderItem is called _Item, for example. The association from an entity view to its text view is usually called _Text.
If there are multiple associations with the same target view, qualifiers are added to the association names, for example, _SenderCostCenter and _ReceiverCostCenter.
Note: Names Reserved for Customers and Partners
When you define your own SAP object types, object node types, or CDS entities, use your reserved namespace /<namespace>/ or the letters ZZ or YY as a prefix. When you extend an SAP standard view, also use your namespace or prefixes ZZ or YY for your own custom field names. Otherwise, name clashes are possible with names of new fields that SAP introduces in a new software version. These clashes can lead to syntax errors and issues during the upgrade to a new SAP software version.
Handling Existing Data
How do these changes to the data model affect planning a migration? The good news is that you’ll only have to take into account a small portion of these data model changes because SAP S/4HANA provides database views with all the necessary compatibility (“Omission of Aggregates” above). However, when planning your migration project, you’ll have to bring your existing data into the new data models.
Depending on the technical migration scenario selected, different technical procedures are used to convert the data. Usually, these procedures include execution of program after import (XPRA) or execution of class after import (XCLA). The XCLA procedure was introduced with SAP S/4HANA 1709 to optimize data conversions in SAP S/4HANA and minimize downtime.
Both procedures take place after the database schema has been adapted. In special situations, certain conversions are made in individual cases in special phases of the Software Update Manager (SUM). Regardless of the scenario you choose, converting the technical data will take some time.
How much time this conversion needs mainly depends on the volume of the data to be converted. For this reason, you should check what existing data can be archived before migrating to SAP S/4HANA. In this way, you can reduce the volume of the data to be converted and thus minimize the conversion runtime. Thanks to SAP S/4HANA’s built-in compatibility mode, applications contain read modules that allow you to read archived data.
Sizing
If you want to implement a new SAP S/4HANA system or convert an existing SAP ERP system to SAP S/4HANA, you’ll have to consider the following issues:
Different Rules Apply for SAP S/4HANA Systems Than for SAP ERP Systems
When planning the hardware requirements (sizing), different conditions and rules apply than for systems based on traditional databases. The main reason for this difference is that SAP HANA stores data in RAM, which requires different sizing requirements. The SAP HANA data architectures and embedded data compression algorithms routinely achieve data compression rates of 3 to 5 on average.
Main Memory Equals Twice the Value of the Compressed Data Volume
As a rule of thumb, SAP recommends estimating twice the value of the compressed data volume as the volume for the main memory. Because sizing strongly depends on your specific conditions (e.g., on the compression rate that can be achieved), SAP recommends running a sizing report in your existing SAP ERP systems. SAP provides detailed information on sizing at https://service.sap.com/sizing.
Conclusion
In summary, the SAP HANA database is more closely linked to implementing application functions than other databases in previous years. This close link is the only way for applications to sufficiently benefit from the advantages of the database.
This close relationship is probably also why SAP S/4HANA is currently only available for SAP HANA. The in-memory databases of third-party providers sometimes follow other approaches and require alternative implementations.
Learn SAP S/4HANA Data Migration in Our Upcoming Rheinwerk Course!
Learn to migrate legacy data to SAP S/4HANA using the SAP S/4HANA migration cockpit. This course walks you through planning, executing, troubleshooting, and optimizing SAP S/4HANA greenfield data migration. Click on the banner below to learn more and order your ticket.

Editor’s note: This post has been adapted from sections of the books Migrating to SAP S/4HANA by Frank Densborn, Frank Finkbohner, Martina Höft, Boris Rubarth, Petra Klöß, and Kim Mathäß; Configuring SAP S/4HANA Finance by Stoil Jotev; and Core Data Services for ABAP by Renzo Colle, Ralf Dentzer, and Jan Hrastnik. Frank Densborn has been a migration expert at SAP since 2004 and is the author of numerous SAP PRESS titles in German and English. Frank Finkbohner is product owner at SAP for the development of the predefined SAP S/4HANA cloud data migration content for the SAP S/4HANA migration cockpit. Martina works in product management for SAP S/4HANA in the area of data migration and data transformation. Boris has been working at SAP since 1999, today as product manager in the Software Logistic area. Petra is an implementation expert for SAP S/4HANA and SAP S/4HANA Cloud. Kim has worked at SAP since 2006, today as senior development manager in SAP S/4HANA Globalization. Stoil is an SAP S/4HANA FI/CO solution architect with more than 25 years of consulting, implementation, training, and project management experience. Renzo is currently responsible for the end-to-end programming model of SAP S/4HANA in the central architecture group. Ralf has been working for several years in the central architecture group of the SAP S/4HANA suite with a focus on the use of core data services in SAP S/4HANA. Jan is a member of the SAP S/4HANA cross architecture team, where he focuses on the virtual data model and the use of core data services in ABAP applications.
This post was originally published 8/2020 and updated 9/2025.



Comments